Jekyll2025-03-21T08:50:45+00:00https://www.tripled.io/feed.xmlTriple DTriple D is a Belgian based software company.My first year at Triple D2022-12-26T00:00:00+00:002022-12-26T00:00:00+00:00https://www.tripled.io/26/12/2022/starting-at-tripledMy first year at Triple D
In February 2022 I joined Triple D and as my first year as employee is coming to an end I will use this as an opportunity to tell what it’s like to join and be part of this company.
It has been an amazing first year for me, and I hope everything below will show you why.
I will start by providing some context on where I was professionally before I joined Triple D, what the recruitment process was like and how it’s been so far.
About me
I am currently 31 years old, have spent 4 years teaching software development and 3 years actually doing it.
A bit over a year ago I was working at a large service provider.
I already had a starting notion of clean code, TDD, architecture,…
In the interview for that job, they asked me what I knew about DDD, microservices, and other techniques or technologies that piqued my interest.
I reasoned that if they want to know how knowledgeable I am about these subjects, they must be using them in practice!
While there was some truth to that, reality fell short of what I had imagined beforehand.
There was the notion that things could and should be done better, but there was never time nor budget to actually make the required changes.
This became increasingly frustrating and eventually led me to look for a new job elsewhere.
Triple D
Triple D was founded by independent contractors who experienced that individually they could not have the desired impact.
They realised that by joining forces it allowed them to reach the high level of support they want to give their clients.
By surrounding themselves with like-minded individuals they could also learn from each other and grow more quickly.
I had found Triple D before when looking for people or companies focussed on software craftsmanship, but then it was in the context of finding speakers for a teaching session at the university college I worked for.
Now I was looking for a job for myself and immediately thought of Triple D again.
There were two quotes on their homepage that spoke to me:
“We” are a group of veteran software engineers with the aim of having a larger, positive impact on the Belgian software industry.
A challenging job well done, that is what we aim for.
These two quotes perfectly captured what I was looking for: people that do not want to just do their job, they want to do it well and they aim to spread the knowledge they have.
That second part hit home for me as I was a teacher before and always hoped to retain some teaching aspects in a future job.
Applying at Triple D
I emailed them explaining the frustration at my current job, my ambition of being a better developer, and how perfectly Triple D’s mission statement matched that ambition.
I quickly received a reply and an initial online meeting was set up.
There we discussed more in-depth what both myself and Triple D were looking for.
As I had hoped, this was a match, and we scheduled an IRL interview.
This was not a typical interview.
Me, Guido and Domenique spent an entire day together, evenly split between paired coding sessions and talking.
We went through a code kata and this in itself was already an eye-opening experience.
It quickly became clear that while I knew some things already, there was so much more to learn.
And these people knew exactly those things!
They showed me in a very clear way that they appreciated what I already knew but also pointed me to where the holes in my knowledge were.
During the time not spent coding, we discussed the state of the industry, shared frustrations, what Triple D aims to do about those frustrations, their vision, what my role could be, and much more.
The relaxed and down-to-earth attitude Guido and Domenique had throughout this day put me at ease and allowed me to show the best version of myself.
They also invited me to one of their Triple Dojo Days.
These are day-long gatherings of like-minded people socializing, discussing and learning from each other.
For me, it was a great opportunity to get to know not only my potential colleagues, but also other people from the community.
For Triple D, it allowed them to see if I was a good cultural fit.
Sander and me during a refactor session at the Triple Dojo Day.
A day or two after the interview they provided me with feedback on how they experienced the interview and what they thought of me.
They liked my attitude and while there was still much I did not know, they saw how motivated I was to learn.
Not much later they made an offer I couldn’t refuse, and we decided on february 1st being my first day working for Triple D.
My first month at Triple D
I spent my entire first month at Triple D learning.
Together with Guido, Kris and Doménique I deepened my knowledge of TDD, DDD, (clean) architecture, refactoring, and learned new things such as Event Storming and Domain Storytelling.
We used the Agile Technical Practices Distilled book as a guide for most of it, but they provided me with other books such as Domain Driven Design Distilled and Implementing Domain Driven Design.
You don’t learn just by reading of course, so all this was supplemented with plenty of time pairing on katas and a larger project.
Having an entire month dedicated to just learning is an amazing thing in and of itself, but having experts on the subject directly available is a great boon on top of that.
It allowed me to quickly ask for clarification when something wasn’t clear and avoided learning incorrect interpretations of new concepts.
My first day on the job, with some reading material
My first client
After the initial month of intensive learning, I started at my first client.
Triple D would have liked to place me with a client together with a Triple D colleague but sadly that wasn’t possible.
The client I’m working at is an old client of theirs: a couple of years ago two-three people worked there.
Triple D knew this client would be a good fit because they are very open to improvements (in contrast with my previous employer).
This means they had a good idea of who was working there, what they were working on, and what the struggles were.
It soon became clear that there were plenty of opportunities to bring my upgraded skills into practice.
Under the guidance of both Triple D and my new colleagues, I was given full support when I saw opportunities for improvement.
This has by now allowed me to take up ownership of multiple small to medium-sized refactors.
I try and do and learn as much as possible by myself, knowing that I can always fall back on the knowledge of my colleagues at Triple D when I reach my current limits.
Personal Development
The text above should already show you how well-supported I’ve been on my learning path.
In addition to the day-to-day support, Triple D has also sent me to DDD Europe, the Socrates Conference and has provided me with plenty of budget to purchase access to other sources of information.
They have met my expectations when it came to helping me reach my full potential, and I’m confident that they will continue to do so.
Conclusion
I realise that most of what I have written can be interpreted as propaganda for my employer.
There’s some similarities with what a new consultant would write a couple of months after signing their contract with your typical run-of-the-mill consultancy company:
“Everything is great here!”, “The people are amazing!”, “My company car is so shiny!”.
The difference is that Triple D has allowed me to turn my back on all the frustrations I had when working at my previous employer, and start developing at a higher skill level.
I have learned even more than I expected, and am sure I will continue to do so.
I now have the skills to have noticeable impact.
My client seems very happy with my work, and so am I.
]]>Harm De WeirdtVocabulary and Validation2022-10-08T00:00:00+00:002022-10-08T00:00:00+00:00https://www.tripled.io/08/10/2022/VocabularyValidationVocabulary and Validation
A discussion that I keep encountering over the years is the following: How and where to handle the validation of your incoming data requests?
Do you validate this data inside your domain model? Or outside your domain model? After all, it is kinda business logic. But do we want the raw data to pollute our domain?
We also don’t want to have the same logic in different places. Since it is then only a matter of time before it gets out of sync and different logic is applied depending on which entry path we take into our application.
What to do if it isn’t valid data? Throw exceptions? Return once we encounter the first data error? Thus forcing the client to correct the data entry one by one?
In this blog post, I’ll try to convey my approach to the topic, hoping that it has some value for someone.
The problem
For clarification purposes, we will use a simple example. A request/command that is received contains a name, a shoe size, and an amount. These simple data fields each have their restrictions.
The name must be at least 2 characters and a maximum of 100. With no whitespace at the front or the end.
The shoe size is a fixed set of valid values. Valid values are [27, 28.5, 30, 31.5, 32.5, 33, …, 46, 47, 50, 52, 56]
The amount must be a discreet positive number. With an upper limit of 1000. If someone is ordering more than 1000 shoes, we need to talk :)
So a possible incoming JSON request can look like this:
{"name":"Guido","shoeSize":"47","amount":5}
With the following as possible implementation:
/** The application API **/publicinterfacePlaceOrderAPI{voidplaceOrder(Stringname,Stringsize,Integeramount)}@RestController()classPlaceOrderController{privatefinalPlaceOrderAPIapplicationApi;@PostMapping("/PlaceOrder")StringplaceOrder(@RequestBodyPlaceOrderRequestrequest){// Do we validate before we invoke the application API?applicationApi.placeOrder(request.getName(),request.getSize(),request.getAmount());// or is the implementation of PlaceOrderAPI responsible for this// And how do we capture and report potential validation errors?returnmessages;}}// The same questions for a possible CLI adapterpublicclassConsoleAdapter{privatefinalPlaceOrderAPIapplicationApi;publicConsoleAdapter(PlaceOrderAPIapplicationApi){this.applicationApi=applicationApi;}StringplaceOrder(StringorderLine){// Do we validate before we invoke the application api?finalString[]split=orderLine.split("\\s");finalStringname=split[0];finalIntegeramount=Integer.parseInt(split[1]);finalStringsize=split[1];applicationApi.placeOrder(name,size,amount);// or is the implementation of PlaceOrderAPI responsible for this// And how do we capture and report potential validation errors?return"Success";}}
Note that all the code used in this blog post can be found in github1
The incoming data will be sent through our application. So the question is: Where and how do we validate the data request? Before or after the internal application API? And how to report any validation errors?
Where do we validate the data?
Definitions
First, we need to start off with some quick definitions, describing the context and high-level architecture in which we will operate. So let’s start with a high-level drawing.
Example application
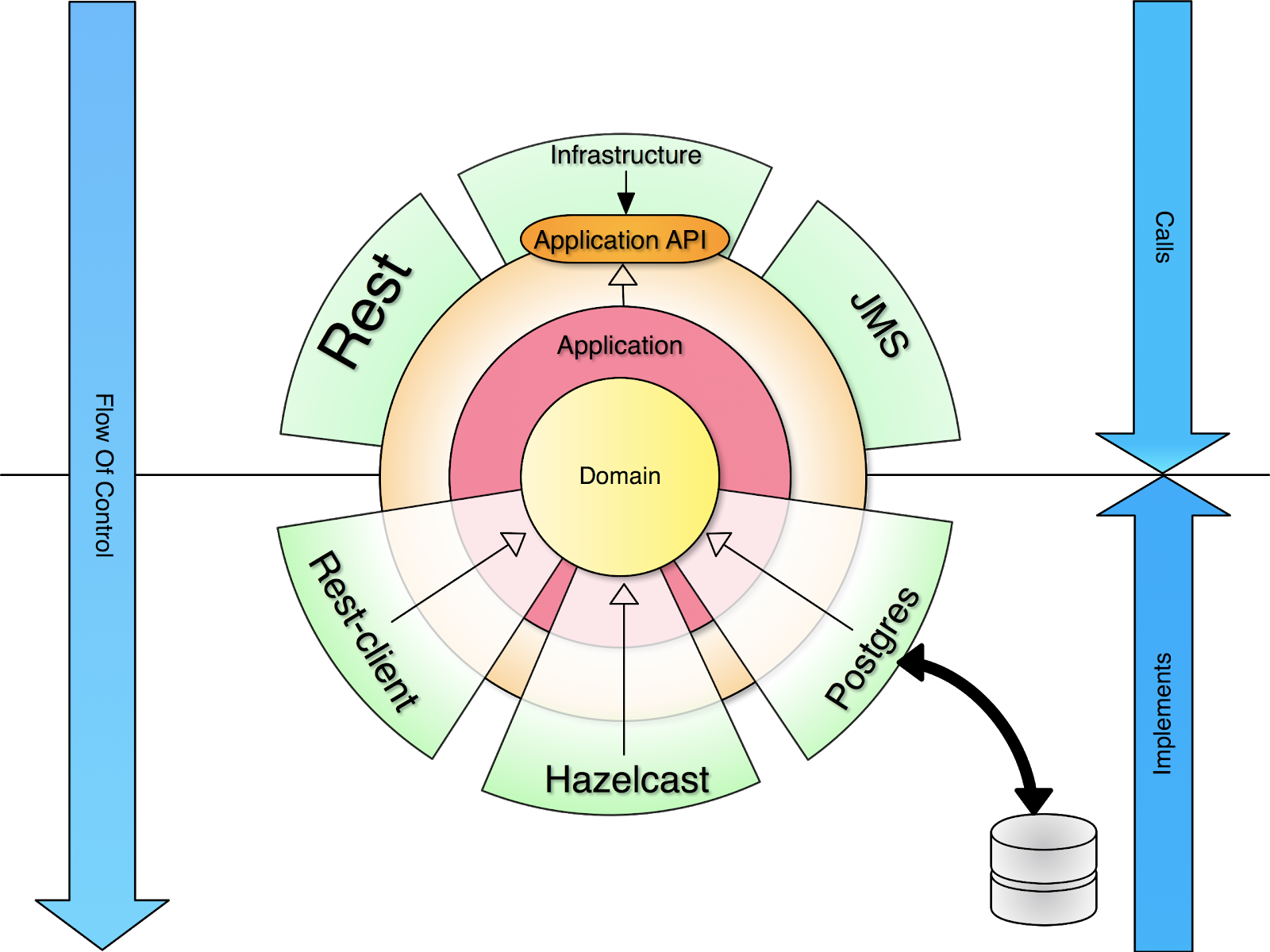
Let’s take as a basis a simple application with a hexagonal architecture. This is not necessary the required architecture, the most important part is the separation between the technically implemented public API that accepts for example JSON, and the internal application API that just talks code and has no knowledge of any external formats. So if you have an internal application API that is separate from the public-facing API, the following discussion is applicable. The discussion we will have will revolve around the following components:
Name
Definition
Layer
A group of modules with a given responsibility
Module
A software module. A jar, dll, …
API Module
A module containing only contracts and the necessary data structures. This (optional) module serves as a separation between modules, to obtain dependency inversion.
Ports
An abstraction/interface that decouples technical implementation concerns from business functionality
Adapters
A module that performs a technical translation/action. It implements a port or uses an API module.
Application
The application is the whole, of all the different components combined, that make up the application. In the old days, it typically was a single deployable but it doesn’t have to be. And this doesn’t change anything for our story.
Public application API
The API that clients use to communicate with us. This is what is available to the outside world. Typically a REST API that can be called by external parties.
Internal application API
The internal API module that exposes the functionality that our application offers. This is a pure code API so it can not be exposed directly to the outside world. There is no knowledge of HTTP, Rest, or JSON here. Just plain old code.
Use cases
The internal application API is typically implemented by transactional use cases. But those implementation details are hidden by the internal application API.
Domain model
Depending on the complexity of your application, there might be a domain model inside that makes it easy to offer the needed functionality. (Note that this has nothing to do with your database model.) But this to is an implementation detail, hidden by the internal application API.
To expose the internal API via the public API, we need an adapter. An adapter is just a module that performs a technical translation. It adapts, as the name says, from one format to another. In a hexagonal architecture, the inbound adapters handle the translation of the exposed public API to the internal API. Important is that we don’t want any business logic inside those adapters because we want to be able for them to be easily interchangeable. A Rest adapter translates the JSON that arrives in the rest controller to concrete calls that are done on the internal API. A CLI adapter could translate command line-level instructions to invocations on the internal application API. Each will have a different translation, but they will arrive, through the internal Application API in the same application. We can easily represent those components as a more classic layered architecture. Where a layer is just a group of modules that can be categorized together.
The application represented as a classic layered architecture
Validation requirements
As mentioned in the beginning there are a couple of requirements we impose on the validation.
1) The validation logic should not be duplicated. If the logic needs to be modified, we want to change it just in one place.
2) There should be no need to do the validation more than once. The applied validation should not get lost. Once something is validated, this information should not get lost.
3) The validation should return as much info as possible. If there are 5 violations, please tell them all 5 immediately if possible. No need to force the client to trial and error.
4) Validating should be part of the normal flow. Normally, validation can have multiple outcomes. No is a normal answer to a question. No need for the code to throw a fit :-). Which is one of the reasons we do not want to use exceptions as part of our normal validation flow. Exceptions are disruptive technically, but they also make for an unclear API.
No need to throw exceptions when there is a validation error
To give some more context to these validation requirements I would like to use a real-world metaphor. Which I think also answers the question “where should the validation occur?”
Security Guards
We can look at our application as a very exclusive club, the hottest place in town, where everyone wants to enter. All the cool kids want to spend their Saturday night at our club. Which is great of course. However, this comes with a responsibility. We need to make sure that it is a safe environment for all our clientele. So for people that come in, we need to make sure that
Everyone is at least 18 years old
No weapons are smuggled inside
People that are on the blacklist are not allowed to enter
Music performers should be on the performer list
Certain constraints are mandatory by law, so we need to enforce those if we want to stay in business. We also want to provide a good experience for the performing artists as well as for our staff. Everyone should want to party with, perform or work for us. Security is a big part of this. Gambling that the only people who walk through the door are all law-abiding citizens is a recipe for disaster. The more well-known our bar is, the more bad elements it will attract. So how would we go about ensuring those constraints without making it a horrible experience?
How to enforce security in our exclusive bar?
We will want some security in place that enforces the given constraints. We can easily see we have the same requirements present for a security check as with a data validation:
We want the security check applied when people come in. Once people are inside, everyone wants to be sure that they met the conditions set to enter. It’s not the barman’s job to check for weapons. So no additional checks should be necessary, it is perfectly safe inside. It is not possible to just walk inside.
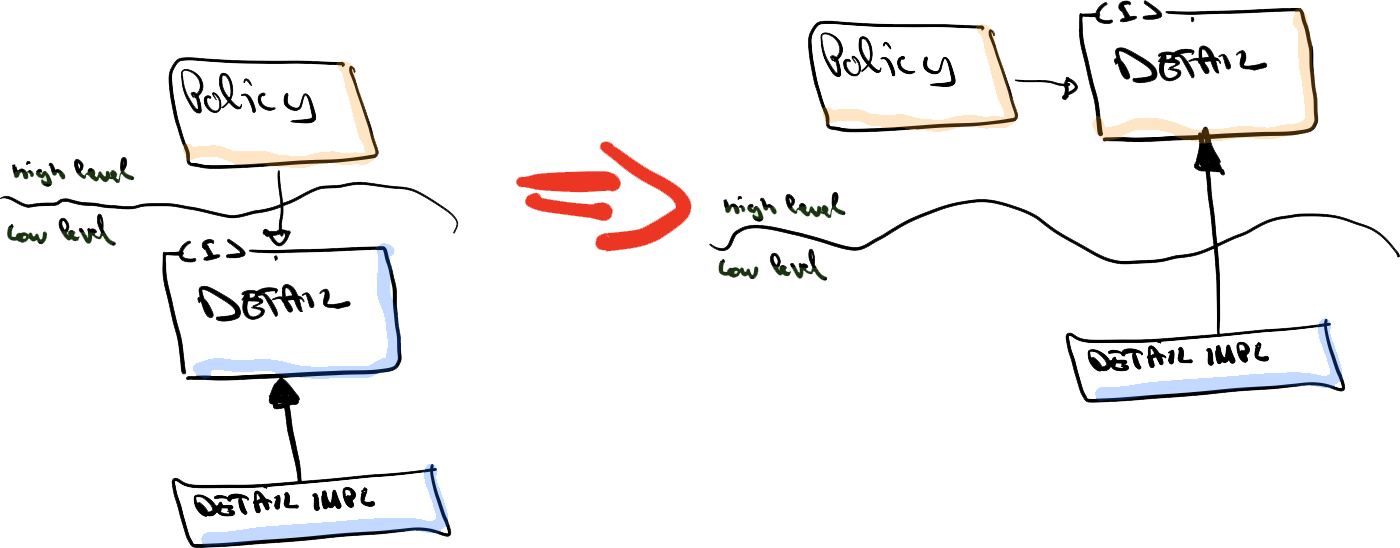
So this answers the question: [Where does validation need to occur?] Before we cross the internal application API boundary. The API guarantees that everything that crosses it is a well-behaving citizen. No validation should happen in the domain model. Because by then it is too late, the party crashers can already be inside.
This leads us to another question: if there is more than one possible entrance, we need to ensure that the same security rules are applied. If the main entrance checks your identity card, but the side entrance does not, then we can all predict what will happen. So the security guards must all enforce the same rules. This maps on the “validation logic should not be duplicated” requirement.
Once people are vetted and identified as Customer, Personel, or Artist, it would be convenient that the people inside can also quickly discern who’s vetted for what. So when someone goes backstage it is immediately clear if they are allowed there. So once inside, we haven’t lost the context of the checks that were made at the entrance. Once you’ve been checked as a registered performer, inside, you don’t need to prove this again. With we can easily do this by handing out badges where needed so that “the applied validation knowledge should not get lost”
Of course, it is also polite that when we refuse people entrance, we let them know why. This maps on the “validation should be part of normal flow” and “validation should return as much info as possible” requirement.
Hopefully, this example gave some context on the why of the requirements we impose on validation. So how does this map to our application?
Enter vocabulary module
Through the security guard metaphor, we determined that we want to perform the validation before we cross the internal application API, which means the validation should occur in the inbound adapter. But given that there is possibly more than one inbound adapter, we now have a problem. Because we determined that we don’t want to duplicate the validation logic across the different inbound adapters. So how do we solve this? How to validate the adapters without duplicating the validation logic across the adapters? By introducing domain primitives grouped in a vocabulary module that can be used by all the inbound adapters.
Enter the vocabulary
The rules for the vocabulary module are the following
The vocabulary module only contains immutable, domain primitives
Everyone inside the application can access the vocabulary module
The contents of the vocabulary module do not get exposed to the outside world.
Be very careful not to turn this module into a garbage bin that is used to circumvent the imposed dependency limitations of your application architecture. The vocabulary module should contain only domain primitives. The convenience of having a module that everyone can access is very tempting. We do want the vocabulary module to be easily changeable. The internal language and concepts of our application do not need to leak to the outside world. So do not carelessly expose it to the outside world. If you refactor the Vocabulary in your IDE, no external contract should get broken.
A Vocabulary is not a garbage bin
Domain Primitives
A well-known pattern, especially in DDD context is Value object2.
A value object is an object
that has no separate identity
models a conceptual whole
is immutable
can be compared with others using value equality
Domain primitives are a special case of value objects. It is a pattern that was named in the excellent book Secure by design3. So let me just quote from there:
A value object precise enough in its definition that it, by its mere existence, manifests its validity is called a domain primitive.
Domain primitives are similar to value objects in Domain-Driven Design. Key differences are that we require invariants to exist and they must be enforced at the point of creation. We’re also prohibiting the use of simple language primitives, or generic types (including null), as representations of concepts in the domain model.
Note that some say that a Value object also has the self-validation property. I follow the original DDD definitions that make the distinction between value objects and domain primitives. If you always let your value objects self-validate: great! Then you are already using domain primitives and your code is more robust for it.
When you are using domain primitives this has the added benefit of avoiding primitives like String and Int in your domain model, avoiding primitive obsession, 4 which I will rant about later. So for now, going back to our example declared in the problem statement, we need a domain primitive for Name, Shoe Size, and Amount that enforces the restrictions we imposed upon them.
The basic Name primitive
publicclassName{publicstaticfinalintMAX_LENGTH=100;publicstaticfinalintMIN_LENGTH=2;publicfinalStringvalue;privateName(Stringvalue){this.value=value;}publicstaticNamename(Stringvalue){if(value==null)thrownewRuntimeException("Name value may not be NULL");if(value.isBlank())thrownewRuntimeException("Name value may not be blank");if(value.length()>MAX_LENGTH)thrownewRuntimeException("Name length may not be larger than "+MAX_LENGTH+". ["+value.substring(0,20)+"]");if(value.length()<MIN_LENGTH)thrownewRuntimeException("Name length may not be smaller than "+MIN_LENGTH+". ["+value+"]");returnnewName(value);}//toString, equals and hashcode omitted for brevity}
The basic Amount primitive
publicclassAmount{privatestaticfinalintMAX=1000;privatestaticfinalintMIN=0;publicstaticAmountZERO=Amount.mandatoryAmount(MIN);publicstaticAmountONE=Amount.mandatoryAmount(1);publicintvalue;privateAmount(intvalue){this.value=value;}publicstaticAmountamount(intvalue){if(isAmountTooSmall(value))thrownewRuntimeException("The amount ["+value+"] must be a larger than "+MIN);if(isAmountTooLarge(value))thrownewRuntimeException("The amount ["+value+"] must be smaller than "+MAX);returnnewAmount(value);}privatestaticbooleanisAmountTooSmall(intvalue){returnvalue<MIN;}privatestaticbooleanisAmountTooLarge(intvalue){returnvalue>=MAX;}//toString, equals and hashcode omitted for brevity}
Code with basic domain primitives be found in github1
Note that in the intermediate examples above we will still throw exceptions, not bothering yet with validations. But it is already impossible to create incorrect domain primitives. They are immutable, correct, and have an actual meaning relevant to the business. By using these domain primitives in our application API, we have already met validation requirements 1 and 2.
The domain primitives as a basic building block of the internal API
Through our security guard example, we’ve determined that the validation should occur before the internal application API. Inside the adapters. So if multiple adapters make use of the internal application API, then they all map their incoming data request to the application API by making use of the shared domain primitives. Once inside the application, no validation should be necessary anymore. By inserting the validation logic inside our domain primitives, which themselves reside in the vocabulary module that can be used by all the different adapters, there is no need to duplicate that logic anymore. It is encapsulated in the domain primitives and all the adapters can access them. So we’ve obtained the first validation requirement: “The validation logic should not be duplicated”.
/** The application api **/publicinterfacePlaceOrderAPI{voidplaceOrder(Namename,ShoeSizesize,Amountamount)}@RestController()classPlaceOrderController{privatefinalPlaceOrderAPIapplicationApi;@PostMapping("/PlaceOrder")StringplaceOrder(@RequestBodyPlaceOrderRequestrequest){// We map the data request, specific to this adapter, to our internal, well-known domain primitives.finalNamename=name(request.getName());finalShoeSizeshoeSize=shoeSize(request.getSize());finalAmountamount=amount(request.getAmountName());//We invoke the API, which is blissfully unaware of any concrete adapter detailsapplicationApi.placeOrder(name,shoeSize,amount);// Let's answer this questions next..returnmessages;}}
If we use only domain primitives in our API and inside our application domain we will have fulfilled the second validation requirement [There should be no need to do the validation more than once]. So by using the domain primitives as the basic building block of the internal API, and performing the mapping in the inbound adapters, we have met the first two of our validation requirements
Primitive obsession
Using no data primitives directly is however a controversial statement. I always encounter a lot of resistance when I advocate having no primitives like String passed on through an application. Which has always baffled me. Because if we have not validated before the data came in, it could contain all kinds of garbage. Like a 300-page XML for example. And if we have done some validation on the data primitives but then pass it on still as a data primitive, we have lost the knowledge of that validation. The main safeguard for knowing what is in a data primitive is the variable name. So that variable name should always be correct, clear and hopefully never misinterpreted.
/** Some function inside our application**/publicinterfaceSomeInterface{//Trust me. I'm a valid businessId and email because I say so.voidcreateInvoice(StringbusinessId,Stringemail)}publicclassSomeClass{//Let's hope the context doesn't get lost along the wayvoidcreateInvoice(Stringb,Stringm)}
This primitive obsession4, when developing in a type-based system has always seemed very contradictory to me. For the “cost” of a simple type, we could make our code so much safer, hard to misuse, and hard to misinterpret. But the mental cost of creating an extra class seems to outweigh those benefits. Luckily this is my blog post, so let me make my final stance one more time: No Strings in my domain! ;D
Please no primitive obsession
Compose domain primitives
Note that in a real application, you will want to combine the necessary domain primitives in a higher-level type. Which can have its own validation and constraints. But it relies on the domain primitives as its core building blocks.
publicclassPlaceOrderCommand{publicfinalNamename;publicfinalShoeSizeshoeSize;publicfinalAmountamount;//details omitted for clarity}/** The application api **/publicinterfacePlaceOrderAPI{voidplaceOrder(PlaceOrderCommandcommand)}
Validation
Using the basic domain primitives in our adapters we have met the first two of our validation requirements. So how will we tackle the other two requirements? Namely, letting “The validation return as much info as possible” and making “Validating a part of the normal flow”?
Notification pattern
To gather all the validation information in one go we can make use of the notification Pattern5 to gather all the validation messages. In my code example, we will introduce a new class ValidationResult that will capture all the validation messages.
// The validation result as an implementation of the notification patternpublicclassValidationResult{publicstaticfinalValidationResultEMPTY=ValidationResult.builder().build();publicfinalList<String>messages;privateValidationResult(Builderb){messages=Collections.unmodifiableList(b.messages);}publicstaticBuilderbuilder(){returnnewBuilder();}publicstaticValidationResultcreate(StringsingleMessage){returnValidationResult.builder().addMessage(singleMessage).build();}publicValidationResultmerge(ValidationResultother){returnValidationResult.builder().addMessages(this.messages).addMessages(other.messages).build();}publicbooleanisEmpty(){returnmessages.isEmpty();}@OverridepublicStringtoString(){return"ValidationResult{"+messages+'}';}publicstaticclassBuilder{//Basic builder pattern impl}}
Note that using Strings in the ValidationResult here is ok. We are creating the Strings ourselves, placing them in a primitive with a clear purpose which is to serve as information for the outside world. A validation result should not be crossing the application API inward.
Validation part of normal flow
We want to make validation part of a normal flow. So that the creation of a domain primitive can have two answers. The requested domain primitive or the reasons why the domain primitive could not be created. As explained before this should not be exceptional but part of the normal flow. It is the same principle/pattern as in Railway oriented programming. 6
So let’s introduce a second class, FactoryResult, which contains the result of the factory or the reasons why it could not be created.
publicclassFactoryResult<T>{privatefinalTcreatedInstance;privatefinalValidationResultvalidationResult;privateFactoryResult(TcreatedInstance,ValidationResultvalidationResult){if(createdInstance!=null&&validationResult!=null)thrownewRuntimeException("A factoryResult may not have a createdInstance and errorMessages");if(createdInstance==null&&((validationResult==null)||validationResult.isEmpty()))thrownewRuntimeException("A factoryResult must have a createdInstance or errorMessages");this.createdInstance=createdInstance;this.validationResult=(validationResult==null)?ValidationResult.EMPTY:validationResult;}publicstatic<T>FactoryResult<T>success(Tt){returnnewFactoryResult<T>(t,null);}publicstatic<T>FactoryResult<T>failure(List<String>errorMessages){returnnewFactoryResult<>(null,ValidationResult.builder().addMessages(errorMessages).build());}publicstatic<T>FactoryResult<T>failure(String...errorMessages){returnnewFactoryResult<>(null,ValidationResult.builder().addMessages(Arrays.stream(errorMessages).toList()).build());}publicstatic<T>FactoryResult<T>createIfValid(ValidationResultvalidationResult,Supplier<T>factoryMethod){if(validationResult.isEmpty())returnFactoryResult.success(factoryMethod.get());elsereturnFactoryResult.failure(validationResult);}publicstatic<T>FactoryResult<T>failure(ValidationResultvalidationResult){returnfailure(validationResult.messages);}publicvoidonSuccess(Consumer<T>happyPathHandler){if(hasValidInstance()){happyPathHandler.accept(createdInstance);}}publicvoidonFailure(Consumer<List<String>>errorHandler){if(hasNoValidInstance()){errorHandler.accept(validationResult.messages);}}publicTmandatoryValidInstance(){if(hasNoValidInstance())thrownewRuntimeException("A valid instance was expected but there were unexpected errors "+validationResult.toString());elsereturncreatedInstance;}publicValidationResultvalidationResult(){returnvalidationResult;}privatebooleanhasValidInstance(){returncreatedInstance!=null;}privatebooleanhasNoValidInstance(){returncreatedInstance==null;}}
We will place these two classes also in the Vocabulary module. ( Details on github ) You could argue that they are not part of the domain but are a mini-validation framework. But since they are two immutable classes that are part of our normal flow I consider them domain primitives and part of the Vocabulary.
Domain Primitives with Validation
Using the ValidationResult and FactoryResult, we can modify our earlier domain primitives so they no longer throw exceptions on a validation violation.
The Name primitive with validation
publicclassName{//...privateName(Stringvalue){this.value=value;}//No exceptions were thrown during the making of this domain primitivepublicstaticFactoryResult<Name>name(Stringvalue){if(value==null)returnfailure("Name value may not be NULL");if(value.isBlank())returnfailure("Name value may not be blank");if(value.length()>MAX_LENGTH)returnfailure("Name length may not be larger than "+MAX_LENGTH+". ["+value.substring(0,20)+"]");if(value.length()<MIN_LENGTH)returnfailure("Name length may not be smaller than "+MIN_LENGTH+". ["+value+"]");returnsuccess(newName(value));}//... }
The Amount primitive with validation
publicclassAmount{//...publicintvalue;privateAmount(intvalue){this.value=value;}//No exceptions were thrown during the making of this domain primitivepublicstaticFactoryResult<Amount>amount(intamount){finalValidationResultvalidationResult=validate(amount);returnFactoryResult.createIfValid(validationResult,()->newAmount(amount));}//...}
The ShoeSize primitive with validation
publicenumShoeSize{SIZE_TWENTY_SEVEN,SIZE_TWENTY_EIGHT,SIZE_THIRTY,SIZE_THIRTY_ONE_HALF,SIZE_THIRTY_TWO_HALF,SIZE_FIFTY,SIZE_FIFTY_TWO,SIZE_FIFTY_SIX;//No exceptions were thrown during the making of this domain primitivestaticFactoryResult<ShoeSize>create(intvalue){switch(value){case27:returnFactoryResult.success(SIZE_TWENTY_SEVEN);case28:returnFactoryResult.success(SIZE_TWENTY_EIGHT);case315:returnFactoryResult.success(SIZE_THIRTY_ONE_HALF);//...case50:returnFactoryResult.success(SIZE_FIFTY);default:returnFactoryResult.failure("Unknown shoe Size "+value);}}
Putting it all together
Now that the domain primitives in our shared Vocabulary module are well-behaved and return a proper response, no matter the outcome of the creation request, all the incoming adapters can map their incoming data requests to the internal application API. Which is constructed from domain primitives. In practice this looks like this:
publicclassRestController{privatefinalPlaceOrderAPIapplicationApi;publicRestController(PlaceOrderAPIapplicationApi){this.applicationApi=applicationApi;}@PostMapping("/PlaceOrder")StringplaceOrder(@RequestBodyPlaceOrderRequestrequest){// We map the data request, specific to this adapter, to our internal, well-known domain primitives.// For simplicity we perform the mapping directly in the controller// For more complex cases, it would be better to extract the mapping logic to a separate mapper classfinalFactoryResult<Name>name=Name.name(request.getName());finalFactoryResult<ShoeSize>shoeSize=ShoeSize.create(request.getSize());finalFactoryResult<Amount>amount=Amount.amount(request.getAmount());finalValidationResultvalidationResult=name.validationResult().merge(shoeSize.validationResult()).merge(amount.validationResult());if(validationResult.isEmpty()){//We invoke the api, who is blissfully unaware of any concrete adapter detailsapplicationApi.placeOrder(name.mandatoryValidInstance(),shoeSize.mandatoryValidInstance(),amount.mandatoryValidInstance());return"Success";}else{returnvalidationResult.toString();}}}
Now we have met all of our initially imposed validation requirements. No exceptions are thrown and all the necessary information is available in one go. And we have an expressive Vocabulary and application-api on top of it.
A little bit of refactoring
The code above was kept as is for clarity. But of course, we want to refactor it a bit more. Extracting the mapping logic outside the adapters, placing the arguments from the API together in a composite… After a bit of refactoring it could look as simple as this:
publicclassRestController{privatefinalPlaceOrderAPIapplicationApi;publicRestController(PlaceOrderAPIapplicationApi){this.applicationApi=applicationApi;}@PostMapping("/PlaceOrder")StringplaceOrder(@RequestBodyPlaceOrderRequestrequest){finalFactoryResult<PlaceOrderCommand>result=PlaceOrderMapper.mapRequestToCommand(request);returnresult.process(this::placeOrder,this::validationErrorsToMessage);}privateStringplaceOrder(PlaceOrderCommandcommand){applicationApi.placeOrder(command);return"Success";}privateStringvalidationErrorsToMessage(ValidationResultx){returnx.messages.toString();}}//The mapping logic is moved to separate mapperfinalclassPlaceOrderMapper{//...staticFactoryResult<PlaceOrderCommand>mapRequestToCommand(PlaceOrderRequestrequest){returnPlaceOrderCommand.newFactoryResultBuilder().withShoeSize(ShoeSize.shoeSize(request.getSize())).withName(Name.name(request.getName())).withAmount(Amount.amount(request.getAmount())).build();}}
The Console controller would look similar with the mapping logic extracted:
publicclassConsoleAdapter{privatefinalPlaceOrderAPIapplicationApi;publicConsoleAdapter(PlaceOrderAPIapplicationApi){this.applicationApi=applicationApi;}StringplaceOrder(StringorderLine){finalFactoryResult<PlaceOrderCommand>result=PlaceOrderParser.parsePlaceOrderCommand(orderLine);returnresult.process(this::placeOrder,this::validationErrorsToMessage);}privateStringvalidationErrorsToMessage(ValidationResultx){returnx.messages.toString();}privateStringplaceOrder(PlaceOrderCommandcommand){applicationApi.placeOrder(command);return"Success";}}finalclassPlaceOrderParser{//..staticFactoryResult<PlaceOrderCommand>parsePlaceOrderCommand(StringorderLine){finalString[]split=orderLine.split("\\s");if(split.length<3)returnFactoryResult.failure("Unable to parse command. Expected three arguments");returnPlaceOrderCommand.newFactoryResultBuilder().withAmount(Amount.amount(split[2])).withName(Name.name(split[0])).withShoeSize(ShoeSize.shoeSize(split[1])).build();}}
The adapters are only responsible for translating their own specific format to the common application-api and back. They contain no business logic and validation messages are part of the normal flow.
Conclusion
In this post, I have tried to make the case that by being more explicit in our internal API, and by using domain primitives instead of primitive data types, we not only make our code more expressive but harder to misuse. We also gain a well-secured, well-behaving application that is more resilient to bugs and harder to misuse by its clients.
I have taken the purest, most strict approach as how I handle this problem. As always, this is my opinion and in practice there are some nuances and gradations that one could apply. But we most definitely should get over this Primitive obsession thing :-)
]]>Guido DechampsSocrates BE 2022 Un-conference2022-07-10T00:00:00+00:002022-07-10T00:00:00+00:00https://www.tripled.io/10/07/2022/Socrates22SoCraTes BE 2022
A lazy sunny Sunday evening. I just got back refreshed from the SoCraTes BE 2022 unconference and decided to share the positive vibes I obtained.
What is it?
For those of you who don’t know, SoCraTes BE is the Belgian Software Crafters community that
organizes regular meetups at several locations throughout Belgium (Kortrijk, Gent, Leuven…).
The unconference that took place this weekend was a two-day event
where Software Crafters got together to sharpen their skills and have a good time.
The conference
This year, because of Covid, the conference was held during the summer period, which meant the weather was lovely.
There were 45 attendees in total, including the entire Triple D team. Sadly some usual suspects were unable to attend because of the holiday season.
There were some first-timers and some old-timers, some young and some people with… more experience (ahem).
Since there was no school(Belgian schools are closed in July and August), some people brought their families along, giving the whole conference a real vacation vibe. The next generation of Triple D’ers enjoyed it, although that might have had something to do with the ice cream.
Most people arrived Thursday evening at around 18:00. Several arrived earlier, others much later. But, as is in the spirit of
the unconference, there are no rigid, fixed timings, so the conference started on the terras with a La Chouffe in the
evening sun. Greeting old friends and meeting new friends. Catching up after this whole Covid thing. At 20:00, we went to
dinner, and at 22:30, we got together for a short, practical introduction. After which, there was more socializing.
Friday morning at 9-ish (the “time-ish” is a running joke since we hardly ever start on time), despite Erik (our fantastic facilitator!) being up and about at 9:00 sharp, we kicked off the unconference with a general
introduction where Erik explained the spirit and flow to everyone. I was already preparing a code repo for a
session I wanted to do in the bar. But obviously, I was present when we started the marketplace, so I could present a couple of
topics I wanted to tackle. At 11:00, we finished the agenda for the first day, and the conference was in full swing.
The sessions
There were too many interesting sessions and topics to discuss them all here. But I’ll give a quick summary of the
sessions I attended.
Humans in natural state good or evil?
A session where the host of the session was unable to attend because he got caught up in another session. And that’s ok.
An interesting discussion still took place. Whoever shows up are the right people.
Let’s implement Git
A cool session hosted by Michel where the group used ensemble programming to implement Git from scratch.
Very instructive.
Let’s BDD poker
A session where we mobbed on implementing poker in Kotlin starting from BDD scenarios. Not everyone
knew Kotlin, but that’s just one more learning experience that did not hold us back. Mobbing is an excellent
technique for this. The main exciting discussion here was on the level of detail that tended to creep in the BDD scenarios and
what should or shouldn’t be moved to a unit test.
Team Topologies applied
A session from Tim where we discussed the ideas of the Team Topologies book and how
to apply them. A fascinating viewpoint from Mathew for me was
When the level of required communication is greater than the level of actual communication. You can choose to
communicate more. But this only scales so far before it just all becomes distracting noise. Or you can lower the amount
of communication required. This can be done by organizing the teams so that minimal cross-team communication is needed.
Mob programming the hard parts
This session was proposed by myself because I was interested in people’s practical problems when utilizing Mob programming. The group shared some of their experiences, and I shared some of mine.
My key takeaway is this: Senior people can easily forget how much knowledge they have accumulated and how intimidating it can be for a junior to join a group of impatient seniors. Also, when people are stressed, their brain stops working.
Why you should become an IT-manager
A session that we held in the open air. As it was a software conference, I was pleasantly surprised that more
than 20 people showed up for a session on management. And we had a lively and thought-provoking discussion.
One of the best quotes from that discussion I’ll shamelessly steal is:
As a developer, you have quick feedback from your code. As a manager, everything takes much longer, and it goes slower.
But the impact you can have, the change you can bring about as a manager can be more significant than you can accomplish as a lone developer.
These were just some of the sessions people hosted during those two days. But the important part for me is that, at
an unconference, I’m as free as a bird (the law of freedom as Erik calls it). I walk in and out of different sessions. Sometimes I decided to attend no
session. Instead, do a little coding, take a walk or chat with others.
The evenings
After dinner, the group returned to the venue for some lightning talks, board games and football with the kids in the evenings. When the kids went to bed, there was the traditional whiskey tasting available, which paired well with the board games :-)
The end
We had breakfast together on Sunday morning, not fully awake due to late-night gaming followed by some discussions.
After that, we had to say goodbye, and everyone went home. Batteries fully charged :)
Some pictures
Some people brought their own, self-printed 3d printer
Discussing flow and estimates
The great weather allowed for outside discussions
Pair programming with a “toxic” pair
Close at heart
The SoCraTes BE community and its conference lie close to our hearts. The idea of Triple D originated in one of the first conferences.
Over the years, we were able to work together with several of the community members. We are proud to be a sponsor and loved helping organize this great event.
]]>Guido DechampsSix tips for successful ensemble programming2021-10-05T00:00:00+00:002021-10-05T00:00:00+00:00https://www.tripled.io/05/10/2021/Ensemble-programmingSix tips for successful ensemble programming
Ensemble programming… what an experience! We’ve been doing it for six months and found lots of positive things but also a few frustrating things. That’s why we would like to give a couple of practical tips to avoid them. They may sound small or trivial, but they made a world of difference for us.
Make the handover a non-event
Switching roles happens a lot throughout the day, so it’s important to make it go as smooth as possible.
In the beginning we used a tool like mobster, which forces you to stop and switch roles. This tool is very useful to remind you to switch roles, but we found it way too intrusive because every time the mobster screen pop’s up it interrupts the current task. We realised that every time this happened we lost a few minutes switching roles, then lost a few minutes to pick up where we left, and more than often this interrupt resulted in switching to off-topic banter making us lose our train of thought completely.
At some point we started using mob.sh, a CLI tool which helped us smoothen the handover. One command and the next driver can continue. This made the hand-over itself a lot faster, however, there was still an interrupt. This made us think about setting up a procedure to make the handover a disciplined non-event which does not interrupt the flow.
We settled on using mob.sh and agreed on using The following procedure:
the driver does a “mob next”
the navigator (who becomes the next driver) takes over the screen sharing
the navigator does a “mob start”
the next navigator restarts the timer.
All of this happens without saying anything about this routine. If the mob is having a discussion, the discussion continues during this procedure. If the driver was typing, they finish their line, and switches to a terminal to type “mob next” so that everyone can see this and do their part of the procedure.
It’s important to have a procedure that works for you, we settled on the above because it works for us. You should run a few experiments and come up with your own. The important part is that it can be done silently, without interrupting the flow.
Experiment with short cycle times
Focus is an important aspect of ensemble programming. Keeping a group of people focused on one thing is hard, especially for the people who are not driving or navigating. The urge to quickly do something else is high. This is especially true for remote sessions where everyone is behind their pc. The best way for us to avoid this, was to shorten the cycle time. Initially we started with sessions of 30 minutes. for a 4-person team this meant that you would be driving or navigating once every 2 hours, it also means that 1 hour out of 2 you had to fight to not get distracted too much.
After a while we realised that by shortening the cycle times we increased our focus a lot. We managed to shorten the period to 10 minutes, and even tried 5. Of course, this only works if your handovers are running smooth and without any interruptions, so make sure you fix that before tweaking your timer.
Everyone uses their own setup
Ask any developer which IDE is the best, and you will get different answers. Same goes for keyboard shortcuts, operating systems, cli utilities etc. Stop debating about it, embrace it. Let every developer work on their own machine, using their own tools.
Using git to do the code handover has the advantage that you can easily switch laptops too, so do that instead of passing along the keyboard.
Always respect the timer, no matter the state of the code
One of the hardest parts about ensemble programming is letting go of the keyboard. Somehow, you always have the urge to quickly finish that small little thing. The problem with this is that once the timer has passed, nothing stops you from staying on the keyboard for hours. You would think that someone from the team will step in and mention it, but in reality everyone is focused on the task and we all lose track of time.
To avoid this, make sure that the timer goes of on all laptops, not just one and force the driver to stop immediately and start the handover proces. Again, make sure the hand-over runs smoothly without interrupts, otherwise this could get painful.
Less discussions -> show me the code!
When a design choice has to be made, and the team finds itself in disagreement, propose to work out multiple solutions so that they can be compared. It’s always easier to reason about something which is right in front of you rather than something hypothetically. Most of the time, it will be pretty obvious wich solution works best.
The hard thing about doing this is to make sure you work out the proposals far enough so that you can form a conclusion. On some occasions it was hard when switching navigators during this process especially when the navigator turns out to be a proponent of the current solution. To avoid this, let the person who came up with the proposal drive the implementation, it will avoid a lot of miscommunication.
Do retrospectives every day!
Maybe this one does not have that much to do with ensemble programming, but do retrospectives often, especially when starting out. This allows every team member to drive the process towards something they feel comfortable with.
In the beginning we did short 15 min retrospectives at the end of the day. This allowed us to talk about some of the issues we where facing immediately and try experiments daily to optimise our way of working.
Summary
For me the main takeaway after six months of ensemble programming is that you should avoid interruptions in the flow as much as possible. Another takeaway is that ensemble programming requires good communication skills from the participants. Retrospectives are meant to improve the process but also to provide feedback to each other.
Hope this helps and have fun mobbing!
]]>Domenique TilleuilWorking with different environments2021-02-14T00:00:00+00:002021-02-14T00:00:00+00:00https://www.tripled.io/14/02/2021/working-with-different-envsToday, most software engineers will have to work with different environments. These could be environments from separate companies, own testing environments, or the typical examples in one company: development, QA, production.
All these different environments bring some hassles and dangers because we often need to switch between these to check certain things and on rare occasions, modify them.
I’m saying on “rare occasions” because modifications should preferably happen through some pipeline and not from a developer’s machine.
As a rule, we want to avoid manual interventions as much as possible. Because almost every ITer knows a story of accidental deletes in environments.
Let it be deleting secrets on the wrong Kubernetes cluster or Terraform destroy.
Of course, this never happens deliberately, possibly because of a lack of sleep or some distraction.
So with this in mind, and the incentive for continuous improvements, I set out to find a possible solution.
This post will describe what I found to make handling multiple environments easier.
Direnv
Direnv is a shell extension for Unix like operating systems that allows you to load and unload environment variables based on your current directory.
This functionality sounds kind of dull right? But it can be quite powerful. Since the industry is pushing towards infrastructure as code, this is a perfect fit.
If the infrastructure is code, there should also be a git repository containing that code and a folder that we can use together with Direnv.
Use cases
Referencing environments
Let’s say you are using Terraform. Then you will probably have a directory for every environment.
Whenever you run terraform apply in one of these folders, Terraform will apply its state changes to the correct environment.
However, whenever you want to validate anything, like a deployment on Kubernetes or an S3 bucket on AWS, you still have to target the right environment.
Well, remember what I said earlier about loading environment variables per folder? Here is where Direnv comes into play.
We will use Direnv so when we enter a folder, Direnv automatically loads the env variables bound to that folder. You can configure most CLI tools with environment variables, e.g. KUBECONFIG, AWS_PROFILE, … Now we can leverage this to point our CLI tools to the right environment automatically.
You can also leverage Direnv to build and deploy applications with Heroku. There you also need to specify certain environment variables to check or deploy applications.
The Heroku token is unique per application, so you could easily make Direnv work with every Heroku repository by setting HEROKU_API_KEY.
Even when you are not using a tool like Terraform or Heroku, it’s still likely to have a git repository that contains some config files or scripts for specific environments. Or you could make sure that the code repositories developers work in always point to the development environment.
Sharing
You can check in the Direnv configuration into source control, so it gets shared with other team members. Then not everyone needs to configure it themselves, and new team members can use it easily. The security implications are low since the file will not be allowed to execute once someone has changed it.
How
You can find instructions on how to install Direnv on their website here.
For mac, it is straightforward if you have homebrew. Just run brew install Direnv and then add eval "$(Direnv hook zsh)" to your ~/.zshrc file or eval "$(Direnv hook bash)" to your ~/.bashrc file and source it or restart your shell.
Now you’re ready to start using it! In the directory where you want Direnv to control the environment variables, you need to create a .envrc file. Below you can find an example of a .envrc file.
This file will point kubectl to the development cluster and aws to the development profile together with the eu-central-1 region.
Since executing this file could be potentially harmful, you need to allow Direnv to run it with Direnv allow you will have to repeat this every time you make changes to the file in another editor. The way Direnv knows that a file is changed is because of a hash it keeps.
Another way to change the file contents is with Direnv edit then you won’t need to reallow the file.
I referenced in the use-cases that you could put the configuration file into source control. The fact that you need to reallow the file whenever someone made changes is what makes it secure.
Now, whenever you enter the folder, it will print the following:
and when leaving it:
After the .envrc file unloads, any overridden environment variables will restore themselves.
Now, if the file has changed and it is no longer allowed, then Direnv will print the following message if you enter the folder:
Conclusion
You can use Direnv to efficiently couple the infrastructure as code folders with their respective environments to make fewer mistakes. Or make sure that your code repositories point to the correct development environment with the application’s deployment.
It can also easily be shared between team members so everyone can benefit from it. This way, everyone’s config will be similar, and the chance of users’ errors will be lower.
In a future blog post, I will elaborate on how you can create some nifty stuff in combination with some other shell features.
]]>Gert VilainCommunication is a Skill2019-09-12T00:00:00+00:002019-09-12T00:00:00+00:00https://www.tripled.io/12/09/2019/communication-as-a-skillCommunication is a skill
Being able to have a productive discussion is an important skill to have. Of course we all try to reduce the boring bureaucratic meetings as much as possible. But we still need to sit together with our fellow team members and colleagues to discuss, refine and agree on how we will build and integrate our software.
As software engineers, we are constantly learning new technologies, new techniques. People their resumes are more often than not a list of hard technical skill that they have mastered. However, engineers rarely take the time to improve their communication skills. Conway’s law taught us the correlation between software design and people interactions. So if we want to develop good software, the interactions of the people that are building it really does matter. A lot. How they communicate with each other is important. It is a skill just like any other. So how can we get better at it?
Does this matter for a software engineer?
In and outside of meetings we are constantly in communication with each other. So you might think that you have mastered this from daily practice and don’t need to spend any time on improving those skills. Communication and collaboration is something that we do every day, so we assume that we are good at it. But I fear that we overestimate our level at effective communication.
No doubt we all have been in some very unproductive discussions where conflicting interests and opinions collide, where a lot of time is wasted with little to show for, except some frustration and possible bad feelings towards each other. Meetings and discussions aren’t productive or efficient by chance. There is a reason people often try to avoid them.
Those inefficient discussions are something that I have started to pay a lot of attention to, in the last couple of years. And once you see the patterns, it is hard to unsee them. It becomes all the more apparent what a blocker they often are for the quality of our software, the speed with which we deliver it, how much time and money gets wasted and how much grievances these unproductive discussions lead to.
So having productive discussions is important. Experience has shown me that it isn’t something that happens from itself. It is something one needs to work on and pay attention to. You could, of course, spend your valuable time on something else than a blog post on communication. This certainly won’t gain you the same bragging rights as having read the latest shiny object article. But I would argue it is a skill that will have more impact on your efficiency as a software engineer then that new fancy framework.
Anti Patterns
Let me start by listing some - what I call - anti-patterns of having a productive discussion
Interrupting each other: Frustrating for the one who is interrupted and makes it hard to follow the conversation. often also a clear sign you weren’t trying to understand.
Raising our voice: The best way of silencing the ‘opposition’. However, when no one no longer objects, that doesn’t mean you made your point. They just stopped caring.
Getting sidetracked: Jumping from one topic to another makes it hard to follow and nothing gets finished.
Going depth-first instead breath first Discussing details in depth before the bigger global picture is clear
Not listening Talking next to each other and not really listening. Just waiting until someone else has stopped talking
No visualization People fearing the whiteboard.
Limited engagement Only a small percentage of the group is engaged: This is a great tell sign that de discussion has gone off the rails. If a large part of the group is no longer actively listening, this should be a sign that something is going wrong.
Ego: Of course. The always present elephant in the room. You are not your solution. Let it go.
I’m sure we all know and recognize those anti-patterns, hopefully realizing that they can be a problem. But knowing them does not mean that we aren’t doing them ourselves. Even if we recognize that we shouldn’t.
I think it is the first major important step to recognize the large cost of those anti-patterns. These anti-patterns impact the quality of the software that we create, the speed in which we create it and the quality of the human relations and interactions. Once we become mindful of this, we can start avoiding these anti-patterns.
Mob Programming
When I recently took Woody1 Zuill’s mob programming2 course, a lot of what he said resonated with me. Not just on how to do mob programming, but on the whole communication aspect. After all, if a team wants to be able to Mob program efficiently they must be also able to communicate productively. Woody taught us Mob programming through a series of exercises where we needed to interact disciplined and pay attention to how we communicate. I found this very revealing.
What “Woody” said
Learn to shut up
By adding our solutions or suggestions non-stop to the discussion, we think we’re gaining speed, but actually, we’re slowing down. It is very hard to keep quiet when we “know better”.
“Clarity comes when you pause. Count to 10.” - Woody Zuill1
Keep it to yourselves
Let people realize a possible error themselves. Refrain from prematurely adding noise. You may be right, they may be right. Let it play out. It will often go faster, with less confusion and better understanding for everyone. We don’t need to have a consensus on every detail. Perhaps it is not even important in the big picture. So, keep it to yourself. This is hard by the way :-)
“Often, we are just adding noise. Can we keep it to ourselves?” - Woody Zuill
Learn to Listen
Listening is not just waiting until it is our turn to speak. Are we really listening?
“A good listener makes others better thinkers” - Woody Zuill
Have a parking lot
Do not continuously interrupt the flow with new ideas, concerns or tasks. Postpone the details, move them to the parking lot so we don’t get sidetracked. We want to keep our focus during a discussion. Discussing one issue at a time. It is also pointless to discuss a lot of could and maybe’s.
“Talking does not expose reality. Doing does.” - Woody Zuill
Respect each other
How would you like to be treated? Treat others in a way you would like to be treated. Don’t let our enthusiasm for a solution make Bullies* out of us. Check the ego. Make an environment where people dare to make suggestions, mistakes and say they do not know something.
“Treat each other with kindness, consideration, and respect” - Woody Zuill
Train communication in Mob
Mob programming is not something that works everywhere. You need to get good at it. The team needs to get good at it. But even when you aren’t doing it on a daily basis, there is a lot to be learned from a couple of sessions. Try it out at work, in a meetup, unconference, … Pay attention to how hard it is to “Not add noise”, “Shut up”, “Really listen”. It is a great technique to practice communication in itself.
Guidelines
After the anti-patterns, I like to offer some guidelines that can help us in becoming better at good communication, at the risk of sounding fluffy duffy. But these things matter. Once you start paying attention to them you’ll be amazed of their impact and how often that neglecting them is the root cause of problems.
The ‘soft’ ones
a.k.a. The hard ones to master
Kindness
Be gentle and polite. Show concern for others. Value their opinions.
Consideration
Be humble. Our own idea is just one idea. Really consider other ideas
Respect
We can respectfully disagree.
Don’t attack other people’s self-esteem.
No bullying other people into silence
I took the above straight from the Mob programming book. They are short and easy to remember. But very hard to master…
“When we learn how to treat each other well we create a path toward better solutions. So start ‘pretending’ that we are good people” - Woody Zuill
Actionable guidelines
a.k.a. The other hard ones
Don’t waste time on discussing and deciding conflicting ideas.
The best way to resolve conflicting ideas is to act upon them.
See what works by doing it.
Model multiple solutions out.
Discuss on concretes.
Visualize things.
Make a drawing, use post-its. Make it clear what we are discussing and where we are in the discussion.
Letting go of the keyboard, or being the first one in a meeting to step up is a big hurdle to take. People seem to think it is not worth the effort, or maybe fear the attention. But visualizing the topic we are discussing can greatly increase the efficiency of the discussion, speed up the process and making sure that everyone is talking about the same thing.
When we are discussing against a visualization
it reduces the cognitive overload
It isn’t personal. We are discussing a representation, not each other. This makes it often less offensive to disagree.
it brings focus and clarity
Conclusion
Solving technical issues is hard. But so is communication efficiently and productively. Do not neglect this skill. Just like with everything, it is something that we can get better at by paying attention to it. Good communication is important enough to do so…
Triple D during a learning day. Practising communication skills as well as engineering skills
]]>Guido DechampsThe importance of the dependency inversion principle2019-05-07T00:00:00+00:002019-05-07T00:00:00+00:00https://www.tripled.io/07/05/2019/dependency-inversion-principleThe importance of the dependency inversion principle
The dependency inversion principle (DIP) is a well known principle and one of the five SOLID principles. It is at the heart of a lot of software design patterns, frameworks and architectures. This article will try to connect some dots and hopes to provide some additional insight into the application of this core principle.
The principle
The DIP principle states the following:
High level policy should not depend on low level details, instead, both should depend upon abstractions. Abstractions should not depend upon details. Details should depend upon abstractions.
In essence the principle advocates two things. First it states that important things should not depend on details. Which hopefully makes a lot of sense. It also states that these concerns of different importance should be loosely coupled from each other. This should be done by using meaningful abstractions as the middleman.
This may sound simple in theory but it is often difficult to distinguish the important things from the unimportant ones. Also it requires discipline and insight to separate the two properly.
Inverting dependencies
Applying the dependency inversion principle starts by introducing an abstraction between the high level policy and the low level detail. This abstraction removes the direct dependency on the details, decoupling it and thus allows for easier re-use of the important functionality in the policy. By introducing an abstraction, we allow the low level details, which are typically far more volatile then the high level policy, to be interchangeable, without requiring changes to the high level policy.
We call this dependency inversion because the high level policy no longer has a uses relationship with the low level policy but the low level policy now has an implements relationship on the abstraction.
This implies that the high level policy and the abstraction reside on the same level. Which brings us to our next topic.
Where to put the abstraction?
Who owns the abstraction upon which the high level policy depends and why? Where does the abstraction belong? The answer is actually already given in the definition of DIP. When we are ‘inverting’ the dependency, we are in essence going from a high level policy that ‘uses’ a low level detail (the dependency) to a situation where the high level policy ‘uses’ an abstraction and the low level policy now has the inverted relation “implements” (the inverted dependency) towards the abstraction. Since our goal was for the high level policy to no longer depend on the low level, the abstraction belongs with the high level policy.
There is also the cohesive aspect of “reason to change”. Why would the abstraction need to change? Because the one that uses it, requires something different from it. It is the high level policy that has the uses relation to the abstraction. Therefore they belong together.
The low level policies, the details, are just plugins to our important policies.
“Dependency inversion” is not “Dependency injection”
Many developers confuse the dependency inversion principle with dependency injection (DI). But these are two separate things. Dependency injection is a technique whereby one supplies the dependencies to an object. The intent behind dependency injection is to achieve separation of concerns between the construction and the use of objects. It states nothing on the relative importance between those objects or if an abstraction is used.
Dependency injection in itself is a form of the broader technique of inversion of control (IOC). IOC in itself can support DIP. But it is not because we use DI or IOC that we are necessarily applying DIP. No framework can help us determining what is high level and what is low level. Nor with defining the proper abstraction to separate the two.
When trying to apply DIP inside our codebase, we can ask ourselves: “Who instantiates the low level implementation of the abstraction if it’s located in an an other module? Using an IOC container, this is an easy problem. The IOC container could create the instance of the low level module and inject it where necessary. So an IOC container makes it really easy to inject low level details into our high level modules. But we still need to provide the proper abstractions ourselves. And we are still responsible for placing the abstractions in the correct location, next to the high level policy.
So is an IOC container required when one wants to apply DIP? Of course not. We just need some sort of “main” module that wires our application together. The “main” is able to access all the necessary objects and wire them together. This is a purely technical affair that we could handle ourselves but it is a solved problem for which we often prefer the use an IOC. But using a IOC does not guarantee that DIP is applied. It is up to us to define the proper architectural boundaries and policy separations. So DI does not imply DIP and vice versa. Separate things.
Using a IOC does not guarantee that DIP is applied
The principle applied
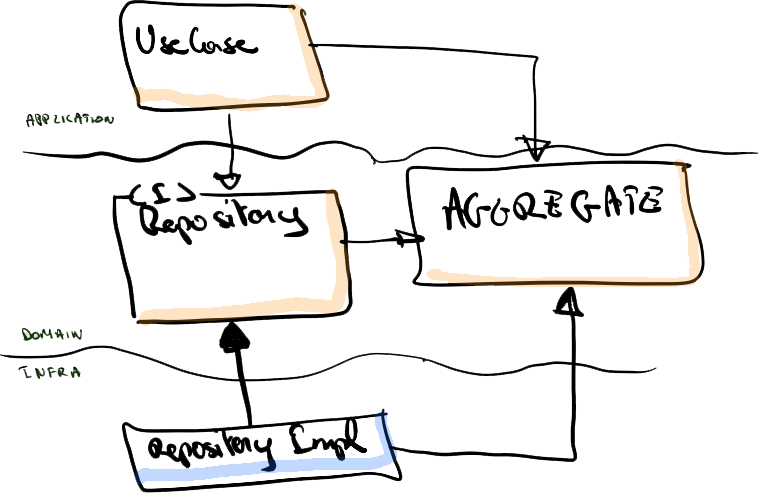
The repository pattern
Looking at the repository pattern, as originally coined by Eric Evans, we can clearly see that it’s a fine example of the dependency inversion principle. The pattern states that an abstraction should be created which is free of technical details, and should preferably look a lot like a collection interface. The abstraction should be implemented in the infrastructure layer where all the technicalities of dealing with a persistent store should be hidden. From the domain perspective, we are talking with a collection-like interface to store the aggregates.
Placing this abstraction inside the domain layer, close to its consumers, ensures that the domain layer is guarded from any changes to the low level infrastructure code. It also makes perfect sense from a usability standpoint since the repository is defined in the domain language. The repository abstraction should be clean, no technical details should leak through the api.
As a side note, the idea of the repository pattern is to abstract away the persistency details. We obtain domain concepts from a repository. Not low level data where we still need to attach meaning to. If we obtain the aggregate from memory, a relational db, a document db or an event sourced system, those are low level details. A repository is not just a DAO.
This architectural style applies DIP as an additional restriction on the multiple layers of an application. As a result all dependencies point towards the centre where the high level policy logic should reside. Therefore the centre is where we hope to find the domain model, the core functionality of the application. Achieving DIP in a layered architecture is achieved by creating abstract interfaces for the low level details. These low level details are typically called the adapters and sit at the boundary of your system. The abstractions are called the ports and are part of the domain layer.
DIP in Kubernetes
In the Container Orchestrator Kubernetes we encounter Ingress which is an API object that manages external access to the services in a cluster. So an Ingress is an abstraction that provides a functionality to services. In Kubernetes, services are an abstraction themselves that represent a logical set of pods. So on both sides of the spectrum we have abstractions communicating with each other. These abstractions decouple the details of pods and external access. Allowing the high level policies from K8 to work without being hindered by the details.
Conclusion
The Dependency inversion principle is an important principle that helps us to decouple the importance things from the details. It protects us from a ripple effect from changes inside low level modules. Because it neatly separates different concerns and allows the important concerns to take centre stage, our software can easily be adapted and understood. It enables the core of our software, the important stuff, to endure and survive the frequent changes in the more volatile lower level modules. It is however not an easy principle to apply. It requires thought and discipline to apply it correctly and consistently. But the benefits far outweighs the effort required.
DIP enables the core of our software to endure and survive the frequent changes of the more volatile lower level parts of the software.
]]>domenique, guidoEvent Storming a restaurant2019-04-09T00:00:00+00:002019-04-09T00:00:00+00:00https://www.tripled.io/09/04/2019/event-storming-a-restaurantEvent Storming a restaurant
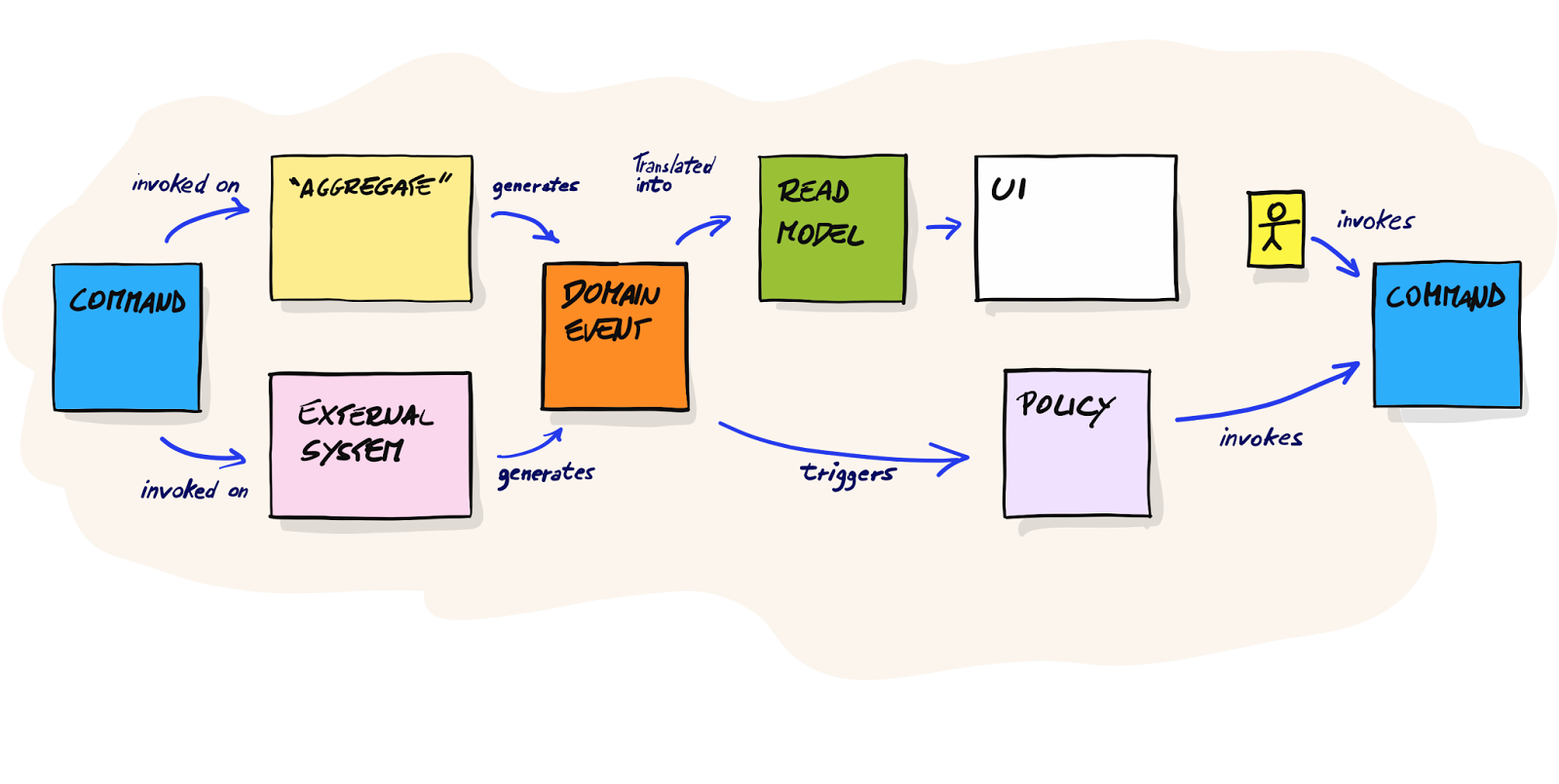
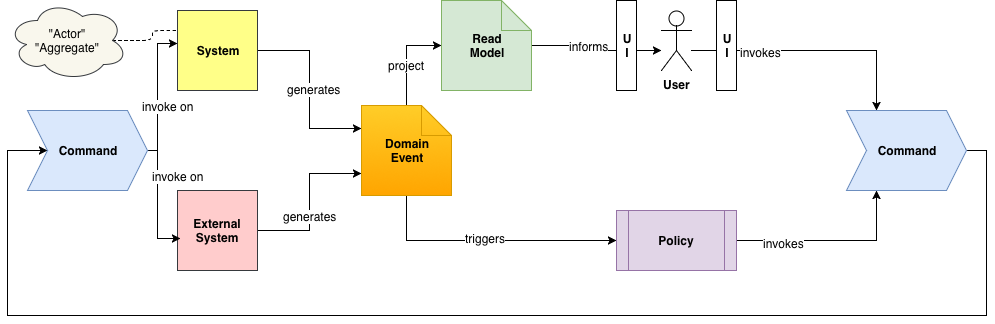
I am a big fan of Event Storming1, a technique that was created by Alberto Brandolini2. Despite its chaotic ‘storming’ nature, Event Storming has the ability to turn confusion into clarity. Because telling a story, on a timeline, is really how people’s brain work. Which is probably why we have user stories and not “user click actions and resulting data flows”.
Most people that use event storming use it for gathering the “Big Picture”. I see it used much less for modelling out solutions to concrete problems. That’s why, in this blog post, I will try to demonstrate the power and usefulness of Event Storming for modelling out solutions. By using some simple building blocks, event storming allows us to model out complex systems rapidly. Without the need for very strict standardization. No BPMN knowledge required.
By explaining the Event Storming component building blocks and illustrating their use, I hope to demonstrate that knowing them, their meaning and their inner relationship, can really help you tackling complex problems. Without the need to get lost early on into technical discussions. One does not need to be a software engineer to model things.
My ambition with this blog post is to demonstrate two things:
As a problem case, I thought that it would be interesting to model out the workings of a restaurant. Because it is something we all can easily relate to. Also, it avoids technology! We can illustrate and reason about it without the need for any technology getting dragged into it. On more than one occasion I’ve seen technical details dragging a design discussion down into an endless technical debate where people are already fuzzing about the technical details before the process is properly understood, modelled out. So I intentionally try to avoid this here.
Welcome to our restaurant
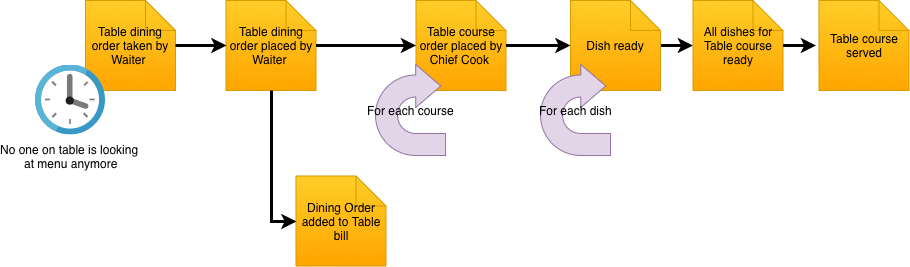
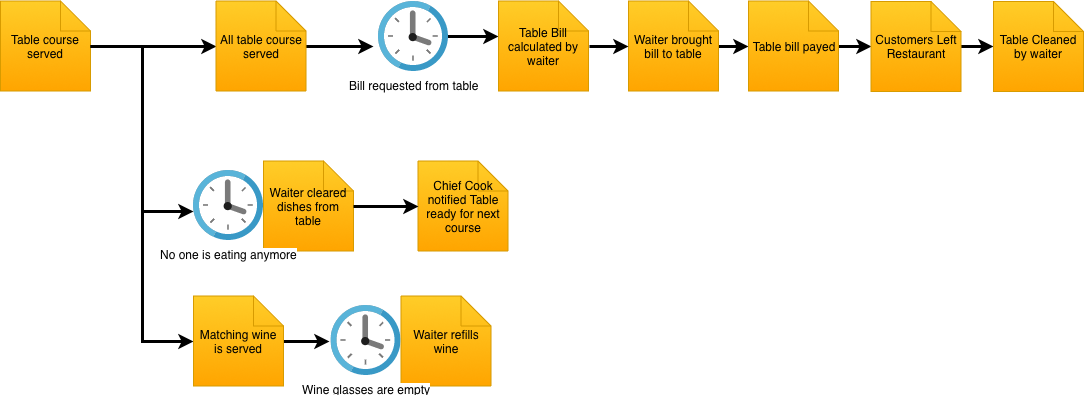
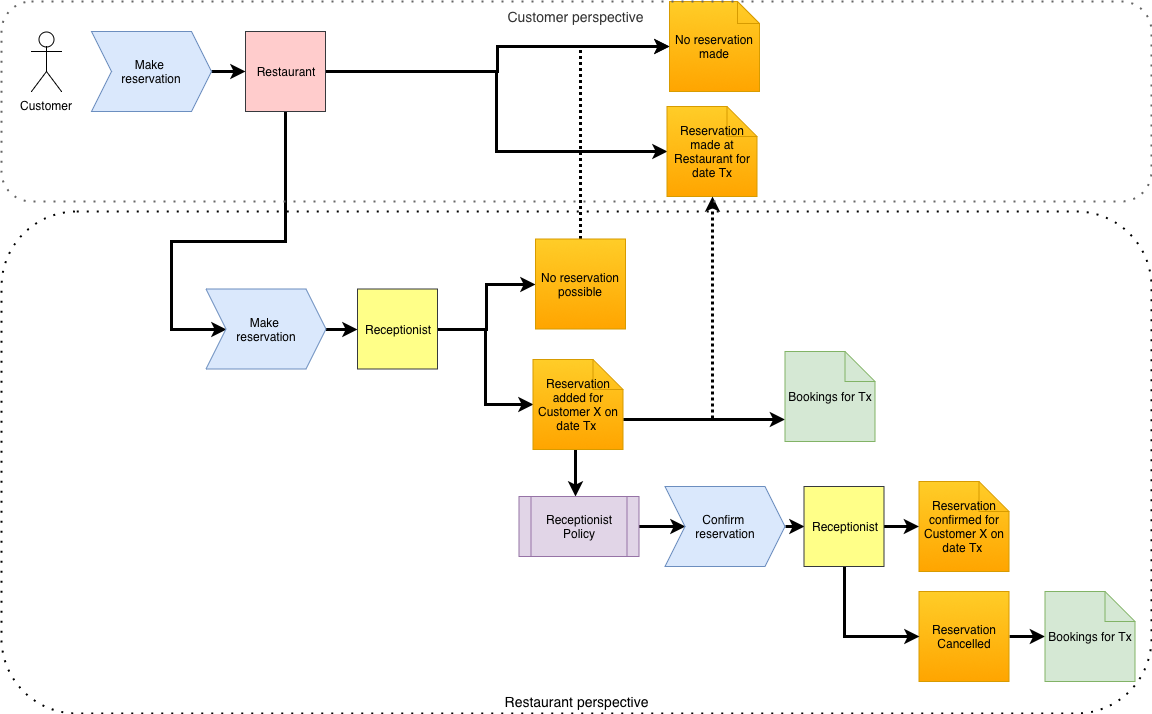
So let’s start with a little background story that illustrates the problems we are trying to solve.
The wedding anniversary
Alice and Bob want to celebrate their 10 years of marriage with a nice dinner at the three-star restaurant “Triple D”. This is a restaurant not only known for the high quality of food and service. But they are unique in the fact that they are also able to serve à la carte. Combining high quality software food and service with great adaptability. So Bob makes a phone call to “Triple D” for a reservation within two months for two persons. The receptionist notes down the reservation. Three days before the date of the dinner, the receptionist of “Triple D” calls Alice to verify if their reservation is still on. Alice confirms that it is.
At the evening of their wedding anniversary, Alice and Bob arrive by taxi at “Triple D”. They enter the restaurant and are immediately greeted by the receptionist. They give their names and the receptionist looks them up in her reservation book. She finds their entry and their appointed table. She then escorts them to their table and takes their jackets. Once they are seated a waiter slowly walks to their table to welcome them. The waiter presents them with the menu.
Alice and Bob start by ordering an aperitif immediately. The waiter leaves to get their drinks and to give them time to make their choice. Alice and Bob look at the menu and discuss what they will have.
The waiter brings the aperitif to their table and serves it to them. They still aren’t ready to order so the waiter leaves again.
After a couple of minutes, Alice and Bob have made their choice out of several dishes. They both will go for matching wines since none of them needs to drive. The waiter sees that they have made their choice and comes over to take their order.
After a couple of minutes, the waiter brings them some appetizers while they enjoy their aperitif and while they wait for the first dish to be served.
The rest of the evening continues smoothly. Alice and Bob enjoy their dinner. The dishes come with an appropriate time between them, leaving room for pleasant conversation, without them needing to wait too long. The waiter makes sure that the correct wines are served and that their glasses are consistently refilled while they are enjoying the matching dish.
After dessert, they order a little digestif and request the check. The waiter brings the check and accepts the payment. After they enjoyed the digestif Alice and Bob collect their jackets and exit the restaurant. After which a waiter cleans their table.
The problem scope
With this little reference story as background, we are going to map out how a restaurant should operate in order to support the above scenario. There are many different actors in the restaurant. More than the one’s Alice and Bob came in contact with. The inner workings of the kitchen, how the bill was composed, to name a few. We also need to remember that Alice and Bob were hopefully not the only customers inside the restaurants. So we need a solution that scales, in which we can serve multiple customers, independent of each other.
The restaurant event flow
In the real world, to discover how the restaurant really works, we would hold a big picture event storming with all the people working in the restaurant present. The Waiters, Cooks, Dishwashers, Receptionists,… This would show all the different flows that are happening, their timing, inner dependencies and potential bottlenecks. Providing everyone with a global overview that most likely no one really has. All of this simply by using the power of business events!
For this blog post, big picture event storming is not the focus. But I would still like to use it to get a global understanding of our restaurant, we are conquering before we are dividing. At the same time, I like to demonstrate the power of business events. Because it is something that bears repeating.
So below you will find my own simplistic event flow for a restaurant, based on my limited understanding and imagination. It is not complete or perfect, having intentionally oversimplified many inner workings. But it tells a coherent story and we can already see different ‘flows’ appearing.
The reservation event flow
Since Triple D is very famous (ahem…), people need to make reservations.
Customer enters restaurant event flow
From our restaurant perspective, the business starts once people enter our restaurant.
Dining Ordering event flow
Once the waiters see that a table is ready to order, they take their orders and passes them on to the kitchen. The kitchen prepares the different dishes and makes sure that they are sent out to the table together.
Courses served event flow
The customers enjoy all their served dishes. Once a dish is done, the kitchen can serve/prepare the next ones. When they are done, a table requests the bill pays and leaves the restaurant. After which the tables need to be cleaned for the next customers.
In the previous example we are able to tell comprehensible stories simply using domain events. We didn’t need to use any other components yet. That is the power of events and why they are the central component that which we will tell our story.
Event Storming components
The domain Event
The core building block of event storming is, of course, the domain events.
Domain events have the advantage that they steer discussions away from technical issues, that they focus on what has happened, without spending too much detail on how it happened. When the discussions occur around domain events then database and UI discussion are pushed to the background. Which is a very good thing. We don’t want to let debates go depth-first from the start because we could waste a lot of time on something that may later seem to be an unimportant detail. We want to conquer before we divide: we aim to understand the problem, see the whole story, before we start splitting things up and start thinking about possible solutions.
All modelling components
Apart from domain events, there are also other DDD building blocks that can take the stage in an Event Storming session. All the building blocks used are:
Component
Description
Contains
users
Actual persons interacting with ‘systems’
Free will
commands
An order that was given, things someone wants to happen. It doesn’t do anything on its own.
Data
events
A business event that has happened.
Data
projections
A data transformation that builds a read model from events.
Data Transformation logic
read models
Information that is presented to a user to make a decision
Data
policies
Global business rules. “When X happens then trigger Y”
Orchestration logic
systems
Something under our control that executes a command. Can be an aggregate, actor,…
Actionable logic
external system
Something not under our control that executes commands.
Actionable logic
UI
The typical portal from the real world to the software systems. The way by which the user can read models and trigger commands in a software world.
Interface to data and actions
Note that these definitions aren’t very formal and precise. This is intentional. One of the powers of the event storming components is that they are not defined too strictly. Event Storming aims to be a very lightweight technique, that is easy to learn and remains flexible. We don’t want to get stifled by heavy standards.
All these components have relations defined between them. As explained in Alberto’s Universal picture.3
The above components come into play when we move away from trying to understand the problem and we start solving it. The moment we want to model out solutions to the story, that’s when we add the other components. In a modelling sessions these components are typically represented by light weight post-its that we can easily move around or replace. We just need to respect their light definitions and their inner relations. This provides us with a fast and cheap modelling technique.
These building blocks can be implemented technically. This means that when we are modelling out a solution through Event Storming process flow, we are also immediately modelling out a different potential software solution. Even if we haven’t referred or included any technologies yet, the modelled solution can map one on one with the implemented one. Which is exactly what we want. The domain should drive the design of our solution, not the technologies. Or god forbid, the database… In a future blog post, we will talk about the relation between the modelling components and a hexagonal architecture. But for now, we will remain technology agnostic.
Modelling our restaurant processes
Armed with the knowledge of our building blocks, we will now model out the flow between the different actors in the restaurant. The customer, the waiter, the cook… I will give a verbose explanation with the first processes. But I hope that after a while the model speaks for itself.
The legend used in the following process illustrations matches:
Since we will remain technology agnostic, there will be no UI. But the other components can be found in the real world. In our restaurant example, they can be implemented as follows
a read model will be data written down on paper
a projection will be the act of writing summarized data down
the events will be things that happened in the real world
the commands are the initiation of an action
policies are the rules that were agreed upon verbally up front
With our building blocks at our disposal, we can model out the flow of our restaurant.
The processes
In the big event flow, there are many different processes at work. For clarity, we’ll distill them one by one, each time with less explanation. The process diagram should make it clear.
The reservation processes
Let’s start with the process that kicks off the customer experience, the reservation process. From the customer perspective, this is very straightforward. They make a call to a restaurant, some external thing outside of their control, and they try to get a reservation for X persons on a given date Tx. The outcome of this is that the reservation was possible or not. This is the flow from the customers perspective. For the customers, the restaurant is an external system. The details of it do not concern them.
From the restaurants perspective, however, these details concern us of course very much. The phone needs to be answered by the receptionist. A role that is taken by whoever is at the desk at the customer calls. The receptionist will see if there is a table available for X persons on date Tx and respond accordingly. If the reservation is made then the receptionist will add it the bookings overview for Tx. The bookings overview is a projection of all the bookings made for a given day. It gives a quick comprehensible overview.
Each day the receptionist need to confirm the reservations made for z days in the future. That is one of the restaurants policies. It is applied to make sure that they use the maximum of their restaurant capacity. Everyone who serves as the receptionist on a given day knows that this is one of their tasks. So the policy triggers them to confirm the reservations with the customers. When a reservation is cancelled they update the Bookings for that day.
At the start of each day, the receptionist needs to assign the final tables to the customers. Since they aren’t likely to change any more this can now safely be done. This is again one of the restaurant’s policies: “When the day starts, then the receptionist must assign tables”. The definitive assignments read model is updated. This will allow the receptionist to be able to quickly assign the customers to their assigned tables.
The receptionist policy thus contains the following rules:
When the date is [Tx - z] then receptionist must confirm the reservations for Tx.
When the date is [Tx] then receptionist must assign the definitive tables for to the booked customers for Tx.
The dinner processes
There are of course more processes operational in the complete working of a restaurant. But let us jump right into the flows concerning the dinner. Because this is the core of our restaurant, where we make our money.
It starts of course with the customers entering our restaurant. They will be received by the receptionist who will look up their assigned tables and escorted them to their places.
Once they are seated, the waiter that is assigned to their table is triggered to bring them their menus, let them order their drinks and dishes. The waiter places the table’s drink order at the bar and continues serving other tables. When the drinks are ready the waiter is triggered.
When the waiter serves the drinks, it is typically also the time that the dinner order is taken. The waiter will place the order for the table in the kitchen. From the waiter’s perspective, the kitchen is an external system. They place their order in, and the dishes will be coming out in the correct order, grouped by a table. But the kitchen of course also has a highly complex flow.
On Policies
Policies are something that is often not modelled out explicitly. But notice how lightweight those policies are. The complexity of how to perform complex actions, like cooking, resides in the systems. These actions do not need to change when we modify the logic present in the policies. This allows us to easily change the behaviour of an entire system.
For instance, when we modify the policy rule from
“When the customer is done eating, then the customer must pay” to “When the customer has ordered, then the customer must pay”
we radically have changed the way our restaurant functions. We went from a restaurant for dining, where one pays at the end. To a fast dining restaurant where you pay up front, allowing for faster change of customers.
Policies can be simple agreements between people or they can be fully implemented in software. A process manager4 is a software design pattern that can be used to centralize policies.
On Aggregates
The DDD aficionado’s will have noticed that I have tried not to mention aggregates. This was intentional. An aggregate has a definition that’s too strict and this might stifle conversation, make it harder for people to explore a model. Same goes for Actors. That is why you can see “Aggregate” between quotes in Alberto’s universal picture. Remember not to get hung up on formal definitions. In Event Storming, an Aggregate is just a yellow sticky…
Conclusion
I hope to have demonstrated the power of Event Storming process modelling to you as a technique that can be used to design solutions, without the need for in depth technical knowledge. Please try them out for yourself. Try to solve an Architectural Kata5 to familiarize yourself with the technique. The more comfortable you are with the components and the technique the easier you will step up and start designing. Start using it, start having the conversations. There is no need to fear the DDD police! Alberto2 is a really nice guy ;-) .
This post belongs to small series of posts. The main post is Heroes.
In this post, I will talk about the hero-bully. This is not the ordinary bully, which may come to mind, i.e. someone that everyone fears, almost nobody likes and who rules by force of intimidation. Rather, what I am talking about here are heroes who are placed on a pedestal by one group and who use the power from their received status to bully those around them that do not follow suit. In this regard, the bully resembles the gunslinger hero. After all, depending on whether you oppose or disagree with them, heroes can become bullies who ‘rule’ by brute force and by the political weight that was given to them. Who would dare to go against the hero of the people?
A hero to some, a bully to others
While they may be feared instead of loved by some or most of their peers, the terrorizing gunslingers may still appear heroes to the people of the town. Their heroes still get the job done and the townspeople (the customers) care about the results. They do not need to collaborate with the gunslingers themselves. Consequently, the bullies remain ‘in power’ by the approval of the townspeople in the one hand, and by intimidating and belittling any potential contenders on the other hand.
Bullies grow in teams
In the software industry, where virtually all development is a team (group) effort, a bully rises just like within any other group of people. Someone tries to dominate the group and force them to do what they want. Especially in large firms where teams are fixed, it is easier for a bully to rise in power and take root because relations have time to grow and become fixed. Bullying takes coaxing and pressuring over time and must build on perceived status. Conversely, when one only needs to work together for a short period of time, it is not so easy to establish a dominant role.
Establishing dominance
Software developers typically try to establish dominance by demonstrating superior knowledge in some technical field. This could be a framework, an application, a language, a technology… It is of course also possible that bullies are truly experts in their field and do know best. Unfortunately, even if one has not really mastered a topic, one can easily fake it by making a lot of noise, spouting buzzwords and professing that the opposing party is a [insert derogatory term here]. Those without technical knowledge can often mistake decibels for competence.
Those without technical knowledge can often mistake decibels for competence.
Typically, the business has no way to know whether the bully is an expert or simply feigning mastery through excellent verbal skills. The fact that bullies are or appear to be experts and/or get the job done, causes them to place their trust in these individuals, which lies at the basis of the perceived status within the group.
Unintentional bullies
The truth is that most of us have the potential to become bullies to some, so it is something to watch out for.
For example, if one is lauded often enough, as the expert or hero that saved the day, then ones ego might start acting up. One can start to assume that they are always right – which nobody ever is. After all, constant public praise is a form of political power as it is a sign of hierarchy.
This type of power can be given officially by the role that you are assigned to in an organisation. For example, Technical Lead, Bla Bla Architect. (The more adjectives the better ;-) But this ‘power’ can also be obtained unofficially by reputation alone. The latter is difficult because we aren’t always immediately aware of the reputation we have obtained. As such, if you are unaware of the political power that you wield, you may end up unintentionally bullying people.
It is my opinion that the best way to avoid bullying is simply by listening to what others have to say. At least hear them out and see if your ideas can stand up against debated arguments. Do not try to ‘win’ by force. This is not to say that if one truly does know ‘best’, you are not allowed to advocate your point. As a professional, it is your responsibility to give the customer the greatest value for their money so one should definitely speak up. But, a point should be made on sound arguments. Not on insults or decibels.
A point should be made on sound arguments. Not on insults or decibels.
Dungeon masters
A while back Alberto Brandolini identified a pattern he called the Dungeon master1. In short, a dungeon master is often the author of the original software and knows the software better than anyone else.
Now the Dungeon master is a position every one of us might find themselves in if we stay at a job long enough. It is not a position of malevolence per se, but rather a natural evolution in a certain direction, heavily influenced by circumstances.
The dark secret of the Dungeon Master is that he knows every trap in the existing legacy software because he was the one to leave the traps around. This isn’t intentional or evil. Knowledge, in the form of accidental complexity, starts accumulating in the head of the Dungeon Master, and silently grows.
The Dungeon Master becomes dangerous when they couple their ego’s to their ‘dungeon’. This will cause them to become a force that resists change and improvement. Because when you criticize the dungeon, you criticize them. Furthermore, if a Dungeon Master is granted a local hero status then the DM can become a major obstacle in the never-ending road to improvement. They will harshly attack anyone that criticizes the existing system, i.e. their dungeon, their baby. Armed with the confidence of being the only person with a true knowledge of the complex system, having a hero status, and possibly some minions, they are in a position which allows them easily to block any new ideas. Changes that must be made, bottlenecks that must be fix, software that needs to be replaced… all of these initiatives can be halted by a bully dungeon master.
While the Dungeon Master in itself is not a force of evil, the bully is. A dungeon master might become a bully. However, a bully that goes unobstructed long enough will often evolve into a dungeon master by choice because they are drawn to the power the DM yield through their unique knowledge of all the traps and pitfalls in a complex system. This makes it almost impossible to go against them.
Conclusion
Employers
As an employer be beware that those that appear to be heroes to you may very well be bullies to others. Beware that you are not left with a couple self-aggrandizing loudmouths, supported by some meek minions, while the competent, constructive professionals who wanted the best for the company have left you without you even noticing it.
Make sure to hear more than one side of the story and be very careful with whom you grant “special” status.
Software engineers
To my fellow Software engineers, I would ask, again, to let go of your ego. People will respect you so much more do. Achieving something together is so much more rewarding than forcing your will upon others.
References
In Alberto’s Dungeon master post he introduces the pattern of the dungeon master. And even mentions the minions. Which could possibly correlate with my definition of minions. ↩
]]>Guido DechampsThe local hero2018-06-26T00:00:00+00:002018-06-26T00:00:00+00:00https://www.tripled.io/26/06/2018/LocalHeroThe Local hero
This post belongs to small series of posts. The main post is Heroes.
Throughout these posts of mine on heroic behavior, my main metaphor has been the wild west. One of the well-known archetypes there is the famous hero gunslinger. In this post, I’ll address the software equivalent of this.
Wild West heroes
In the Wild West, the fastest gunslingers usually become the natural leader. Using their skills to perform various heroic actions, they can gain a reputation with their peers and the local townspeople. The can end up being known as saviours, as someone you can rely on, someone that knows what to do when push comes to shove. Tales of their heroic exploits may spread their reputation far outside the realm of their immediate environment. To most of the locals1, they have become Heroes.
These local heroes are placed on a pedestal by their peers. In some cases, the heroes may even end up being ‘worshipped’ by some of their peers. The more people that place a hero on a pedestal, the more the heroes reputation will grow and the more people will potentially turn to them and start following them.
Software Heroes
Now how does this all relate to software development? Where can those heroes be found in the IT world? In the software world, in a company, the equivalent of heroes are those software developers that carry a lot of weight with their peers, most of the time with management as well. Through whatever actions that they have done in the past, they have earned a good reputation and are considered to be very valuable, almost indispensable. All which are good things you might say.
So let us discuss some of the dangers that lurk in having Local Heroes around.
Dangers of Local Heroes
Ego
Obviously one of the biggest danger for a hero is the ego. Even when the heroes have the best of intentions - and not all heroes necessarily do - it is hard to not get too full of ourselves when everyone considers you exceptional. Because when people are constantly relying on you, give too much weight to your opinion, delegate practically all their judgement to you, then is hard not to start losing objectivity. You may end up believing that you are truly exceptional, and you might very well be God’s gift to the software world, but developing a huge ego can easily have a negative impact on your own performance, and almost always has a crippling effect on the team.
Individuals with a huge ego often are their own main liability and downfall. However, if an ego receives a hero status from their peers the negative impact becomes something to reckon with. Now obtaining a hero status is not something that is always under our own control. It is mostly determined by the environment one operates in. But we can try to rein in the ego at least.
Ego Battling grounds
Now as software developers, we typically tend to couple our ego with our technical knowledge and intelligence. I think it is our equivalent of quick-draws, of showing who’s best. So allow me to quote this little tweet:
The smartest people I know:
Admit they know very little
Constantly seek more info
Encourage intellectual debate
Have strong opinions, loosely held
Are comfortable being wrong
Surround themselves with great people
Realize life isn’t black & white
Fear bias & arrogance
If one really feels the need to, there are better ways of demonstrating one’s intelligence then always wanting to be right. Which is pretty self-evident, we all know this in our day to day life. But in the workplace, this is apparently easily forgotten. Because we typically take pride in our skills in our profession. So a little pro-tip for my fellow heroic super intelligent software engineers out there: Be humble!
Seriously. Everyone wants to be special. But no one knows everything and everyone makes mistakes. Even if it is so much cooler to be a ninja than a janitor. A janitor is useful. Constantly learning and improving yourself is definitely an admirable trait. But that doesn’t make you Gods’ gift to mankind.
Dealing with ego’s
A little mental check that I do is keeping track if I ever heard someone admit that they were wrong or saw them change their minds by someones else argument. When someone can never admit a mistake I try to avoid getting into an argument with them altogether. Their ego has gotten the better of them. No matter how competent they might, personally, I start placing little value on their opinion or ‘arguments’. Because they aren’t being honest.
They are not trying to help, they are trying to win…
Of course, it is normal that people argue and defend their points of view, to a certain point. We all do this to some degree. But if someone is truly incapable of decoupling their ego from their solution then it is impossible to have a meaningful conversation. Because the ego does not permit them to admit that they are not omniscient. So there is really no point in debating them. One is just wasting time and money. That is why, when I am looking for people to work with, I look at their mentality first. No matter how competent or genial you are, the ‘mission’ comes first. We are all smart people. But can we work together?
The hero status complicates all of this. Because if someone with a huge ego has achieved a hero status in a group they are much harder to deal with. Avoiding them is no longer an option. If the local hero has a loyal following, then that can even produce an organizational risk and you’ll need to deal with their minions as well.
Even when someone is capable of keeping one’s ego in check, being ‘worshipped’ is still not a good thing. Even though somewhere deep down, we all like to be the object of adoration, worship runs the risk of stifling the heroes own growth because they are no longer being properly challenged. They can get lazily in their thinking, get too used to ‘being right’. People like to be properly challenged and engaged in their job. Once someone is placed on a pedestal when everyone follows their lead all too easily. this not a challenging environment to be working in. The heroes will leave for more challenging grounds where they can further improve their skills and be challenged properly. Or they will stay and stagnate. Becoming the one-eyed king in the land of the blind.
Lack of ownership
For the software development team, the peers of a hero, and the software that is being developed, having heroes around isn’t without risk as well. The danger of having a Local Hero is that people get lazy, that they stifle their own growth. Because after a while the hero is no longer questioned. Just follow the leader of the pack, be safe, take it easy.
When there are heroes around, people tend not to take ownership themselves. They feel secure in the presence of heroes or intimidated. They run the risk of becoming complacent, just following along, not challenging the leader but also not challenging themselves. No responsibility needs to be taken. They run the risk of not living up to their own full potential. This way, heroes often block the team members from using their full potential, which is not only a waste but also dangerous.
Decisions can get postponed until they get approval by a hero because people don’t want to make the decision or take the responsibility themselves. Or run the risk that a decision taken when the hero was absent will be immediately overturned when the hero returns. This not only starts resembling a dictatorship but it turns the hero into a bottleneck.
This passive behaviour is very dangerous for the software and the company. Because we are all humans.
No one can know everything, think of everything or is infallible.
Even if you should have found some of those mythical infallible IT-heroes, even they can not be everywhere at the same time. The team needs to ready and competent to handle everything without the heroes being around.
That is why we need everyone to pitch in, using all the brain power available. Even when there are people that are more knowledgeable, experienced or ‘smarter’ then you, allow yourself to grow and don’t remain in the hero’s shadow.
It is ok that people seek guidance or mentoring. It is not ok if they stop thinking for themselves.
Emergence of Minions
Even when the heroes have nothing but the best intention, dominating heroes also can complicate the political landscape. It can happen that a little cult of followers starts forming around one person. Even without them actively pursuing this. Apart from the ownership issues mentioned earlier, this is also a dangerous thing politically. Because it adds the additional complexity that next to the existing organizational silo’s, typically present in an organisation, there is an additional group that runs across organizational boundaries. In this case, the leader of the hero cult may gain more power than the organization/ customer is willing to consciously give to them.
The group of minions also can lead to a certain tribalism, a certain group pressure. Us vs them. Where they can gang up on someone outside of the group, under the protection of the reputation of their leader. This can lead to competent people leaving the firm because they aren’t willing to play petty politics and are unable to do a proper job. Again, the customer loses.
Again in the best case, the heroes themselves have only the best intentions. When giving too much power, one might end up using it without knowing it. One might not even be aware that one has power. But the heroes are of course just people. They may give in to the temptation of using that power and risk becoming bullies.
Conclusion
The danger of the heroes lies not so much with the heroes themselves. But more with the impact that they have on their peers. More specifically, the impact their peers allow them to have. Heroes need to take care that they don’t become bullies, that they keep their ego in check. 2 But they themselves aren’t responsible for any passive, worshipping attitude that their peers might develop. If the team, or management for that matter, didn’t consider them as heroes, their ego or at least the impact of it, would automatically be kept in check. The source of the danger is placing someone on a pedestal.
As an employer having your own local heroes may seem comforting and reassuring. Everyone speaks so highly of them, we should treasure them. Just make sure that even the legends can take a vacation or, heaven forbids, change jobs. No one sticks around forever. Everyone must do their part. It is a good thing that the business can place their trust in their software engineers. But this should be the logical consequence of the team doing a consistently good job. No worshipping should come into play.
References
I make the distinction between Local Heroes, which this post talks about, and between some of the very well known names in our IT world (Kent Beck for instance), which this post doesn’t talk about at all. Hence the name ‘Local’ hero. ↩
A book on leadership and people. Chapter 4 deals specifically with the ego. Extereme ownership↩
 Sander and me during a refactor session at the Triple Dojo Day.
Sander and me during a refactor session at the Triple Dojo Day. My first day on the job, with some reading material
My first day on the job, with some reading material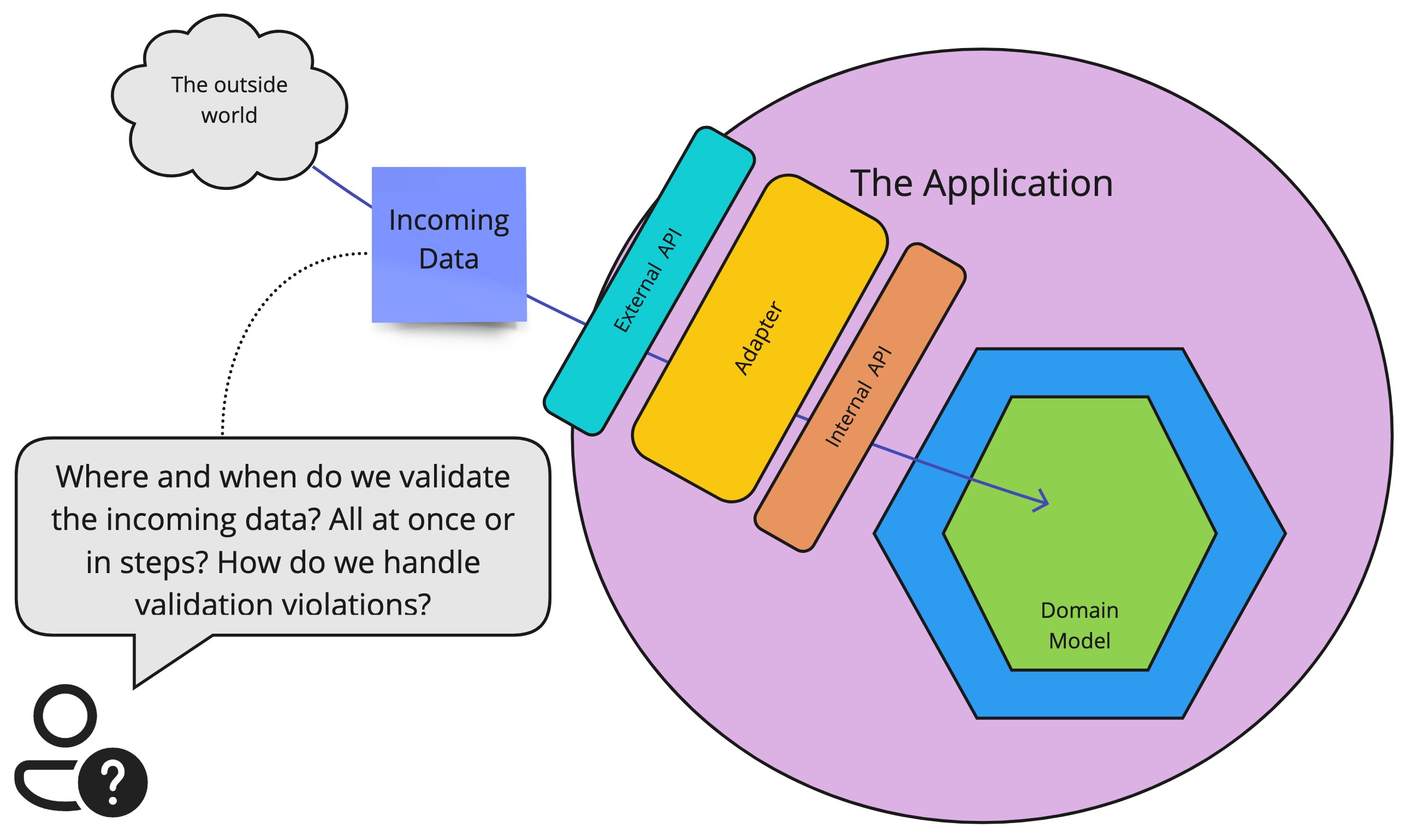 Where do we validate the data?
Where do we validate the data?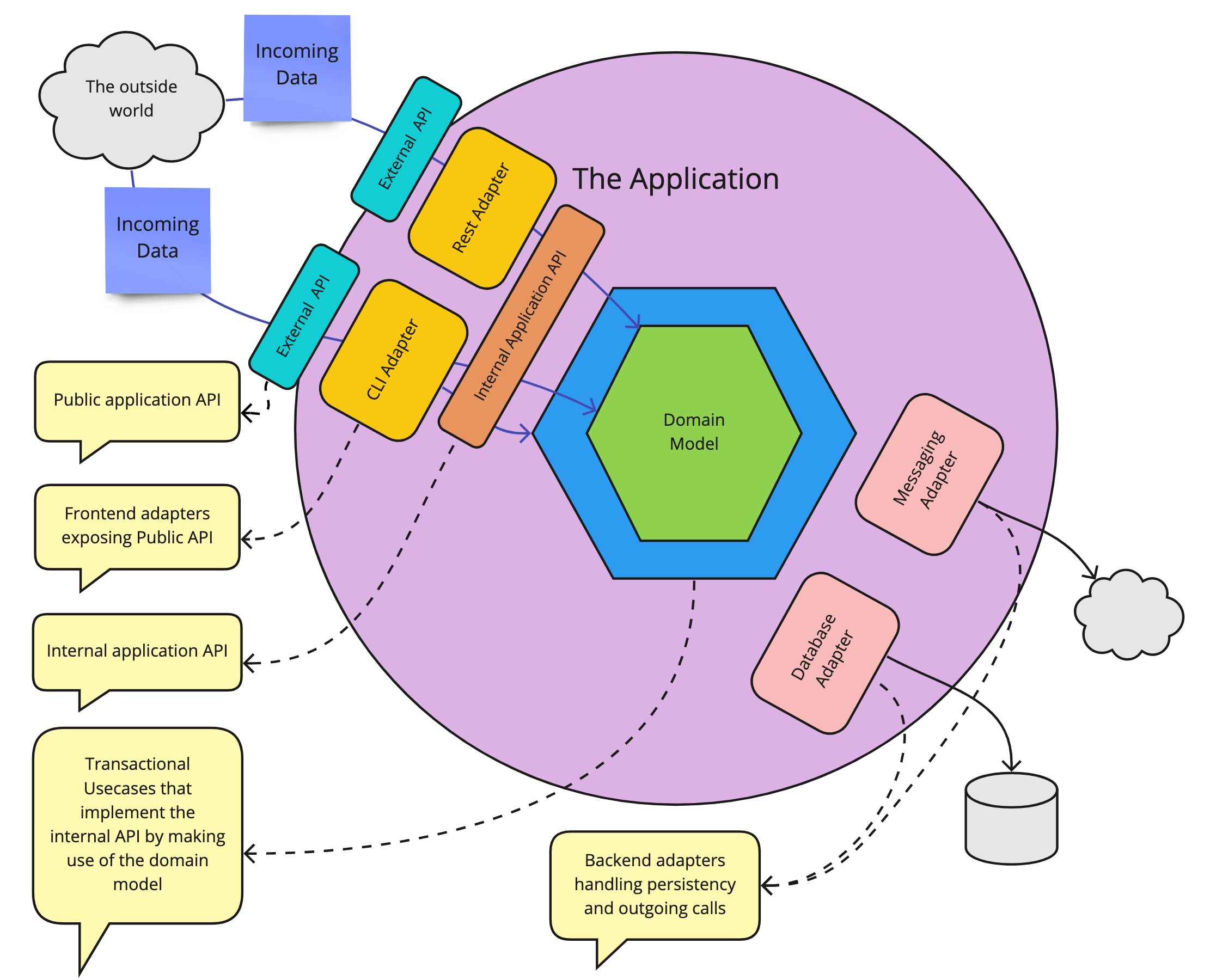 Example application
Example application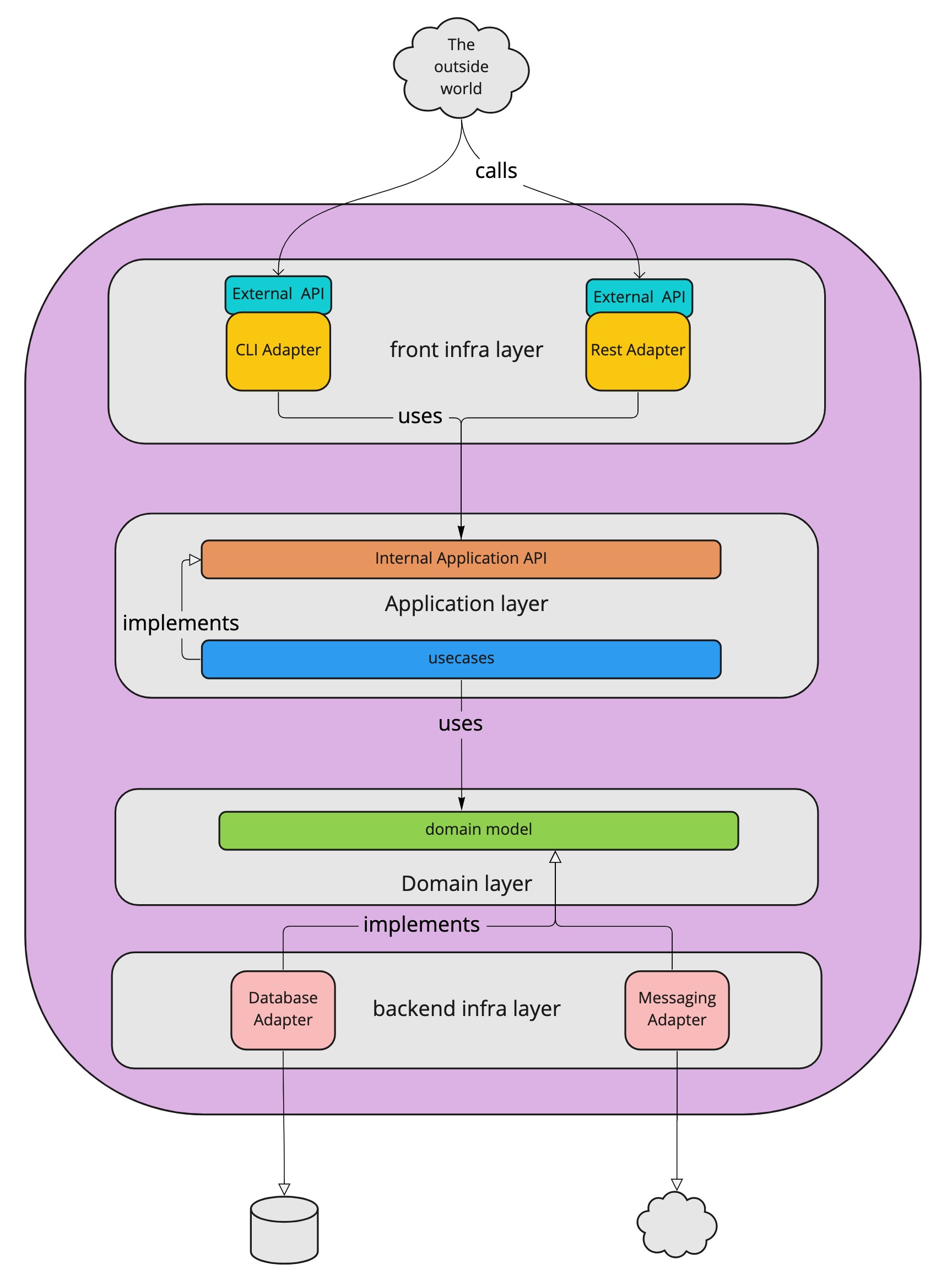 The application represented as a classic layered architecture
The application represented as a classic layered architecture No need to throw exceptions when there is a validation error
No need to throw exceptions when there is a validation error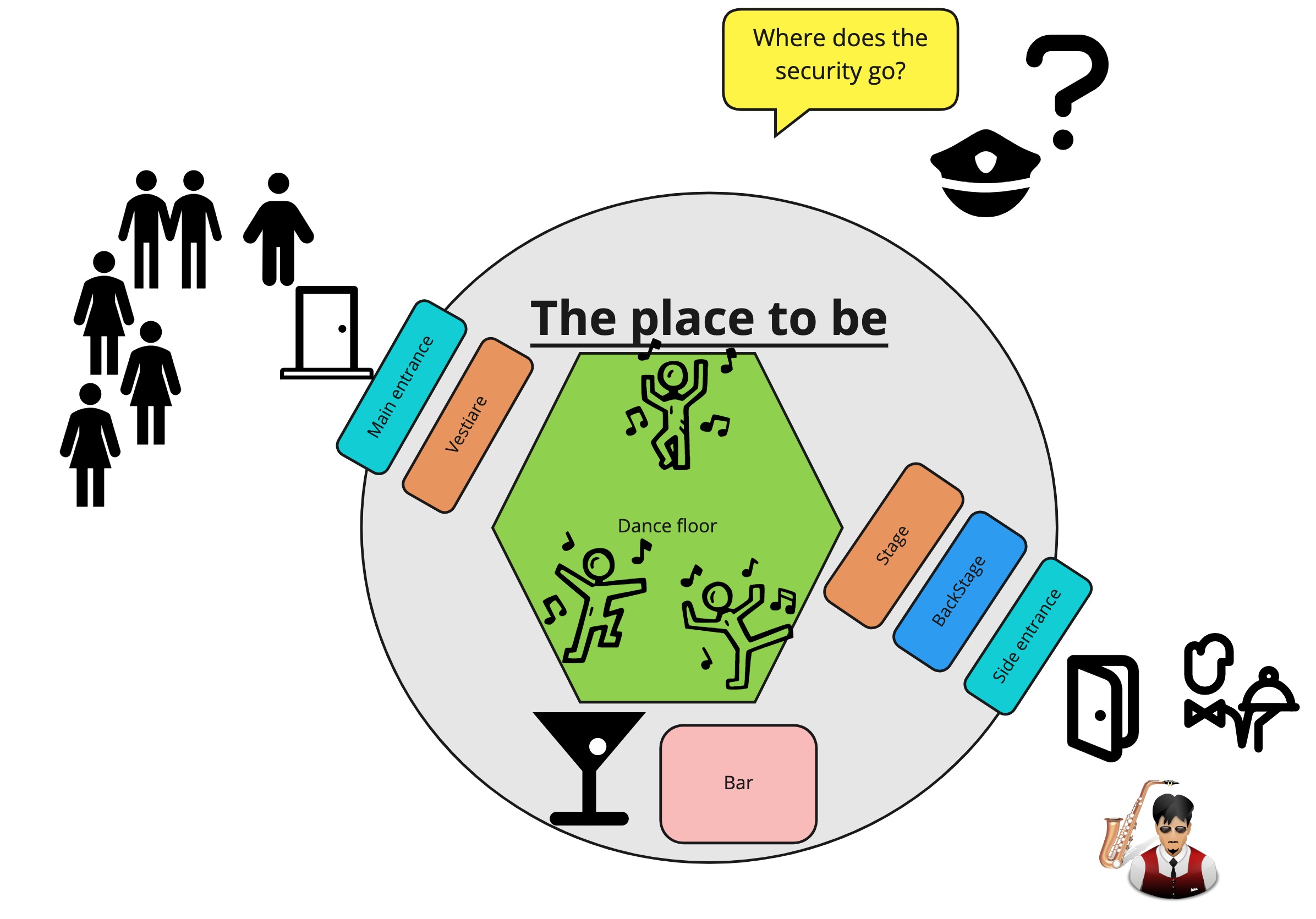 How to enforce security in our exclusive bar?
How to enforce security in our exclusive bar?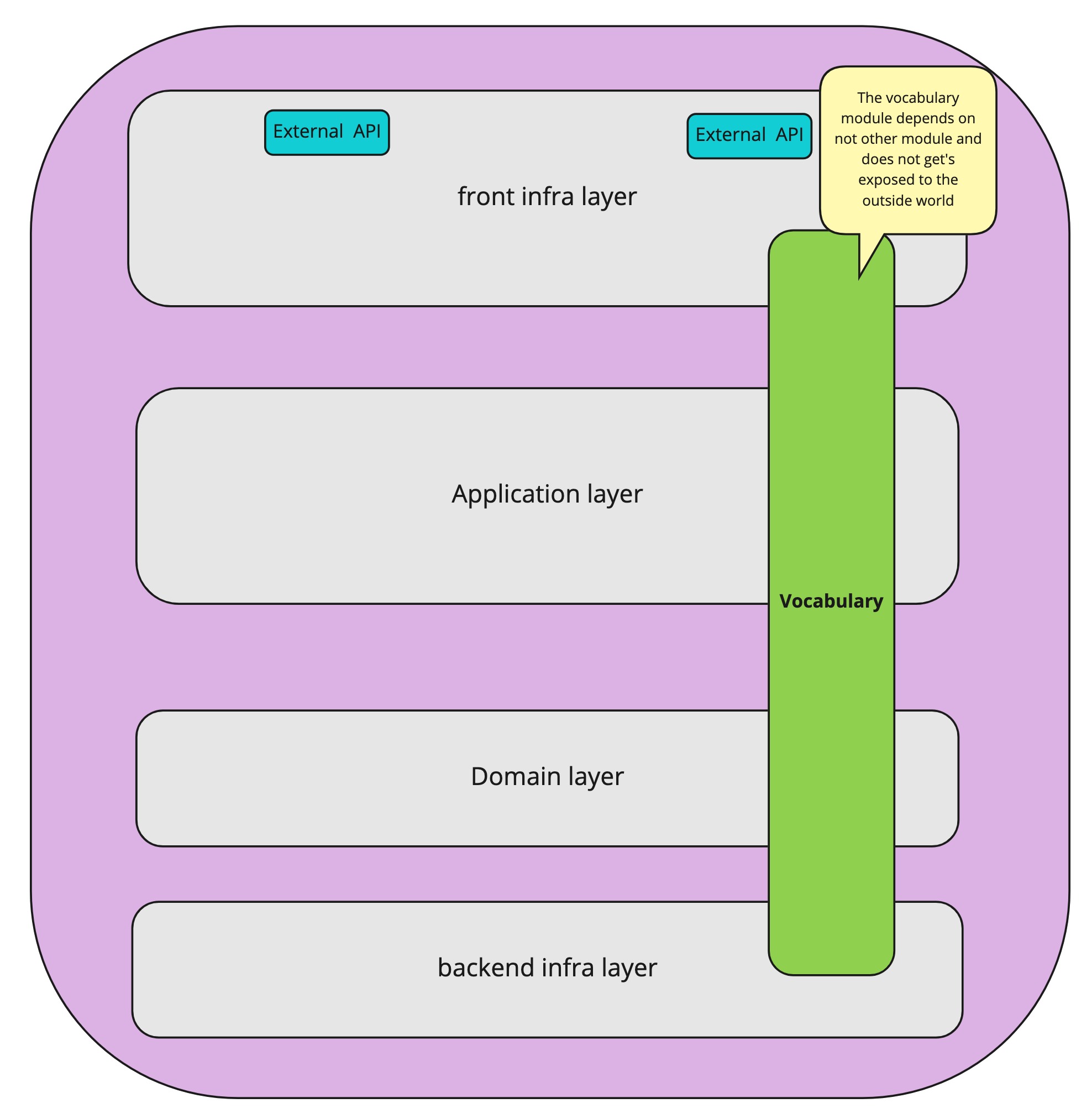 Enter the vocabulary
Enter the vocabulary A Vocabulary is not a garbage bin
A Vocabulary is not a garbage bin Please no primitive obsession
Please no primitive obsession




 Some people brought their own, self-printed 3d printer
Some people brought their own, self-printed 3d printer Discussing flow and estimates
Discussing flow and estimates The great weather allowed for outside discussions
The great weather allowed for outside discussions Pair programming with a “toxic” pair
Pair programming with a “toxic” pair